
Automatiser le déploiement de Splunk sur AWS

Qu’il s’agisse de monitorer leur infrastructure AWS, d’indexer des logs ou tout autre besoin, aujourd’hui de nombreuses entreprises souhaitent déployer Splunk sur AWS. Cette infrastructure étant le plus souvent constituée de plusieurs serveurs, on aura tout intérêt à automatiser son déploiement, non seulement pour gagner du temps, mais également pour fiabiliser le process et s’assurer de toujours déployer le même standard.
Pour bien comprendre l’intérêt de l’automatisation du déploiement de Splunk sur AWS, il nous faut détailler l’architecture d’une infrastructure Splunk. A partir d’un certain volume de données, on ne peut pas se contenter d’un seul serveur pour remplir tous les rôles : pour qu’elle soit plus performante, il faut distribuer l’architecture.
L’architecture Splunk distribuée est composée de plusieurs éléments :
- Indexeur : élément clé de l’architecture, l’indexeur reçoit les fichiers de logs, les parse avec certaines règles définies au préalable, et créé les index. En fonction de l’importance de l’architecture, un seul indexeur peut ne pas suffire. Afin de protéger les données, on peut vouloir que les données soient présentes plusieurs fois. Et que chaque index soit également dupliqué. Dans le cas où on a plusieurs indexeurs, il est nécessaire de prévoir un cluster d’indexeurs, avec un master cluster node pour piloter les indexeurs.
- Search Head : interface graphique dans laquelle on enregistre des dashboards, et à laquelle sont envoyées les requêtes. Searchhead interroge un ou plusieurs indexeurs, qui lui renvoient les données, pour les présenter de façon linéaire ou dans un dashboard. Afin d’équilibrer la charge, il est possible de prévoir plusieurs Searchhead et un loadbalancer. Enfin, dans le cas où il y a plusieurs indexeurs, Search Head interroge le cluster master, qui lui renvoie la liste des indexeurs qu’il peut utiliser pour faire ses requêtes.
- Serveur de déploiement : Splunk permet d’utiliser des applications (fichiers de configuration) afin de faire du “spécifique”, que ce soit pour le parsing, l’indexation ou l’affichage . Certaines applications peuvent indexer, d’autres afficher. Le serveur de déploiement permet de faire des classes de serveurs afin de déployer en un click, une application sur tous les serveurs de la classe appropriée: par exemple une application de “dashboard” ne sera déployée que sur des SearchHead et une application de parsing ne sera déployée que sur les indexeurs. Pour ajouter une nouvelle application, il suffit de la déposer en un point central, le serveur de déploiement. Ensuite, toutes les applications sont déployées de façon automatisée. Dans le cas où nous avons un cluster d’indexeurs, seul le “master” du cluster sera client du “deployment server” et il déploiera à son tour sur les “indexeurs” du “cluster”.
- Serveur de licence : enregistre toutes les licences Splunk, de façon à ce que chaque machine s’y connecte pour verifier ses droits.
- Heavy forwarder : en cas de fort afflux de données, l’Heavy Forwarder pré-indexe et pré-calcule afin de soulager la charge de l’indexeur.
Comment on peut le constater, l’infrastructure Splunk présente une certaine complexité. D’où l’idée d’automatiser son déploiement sur AWS. Cette solution de déploiement automatisé s’appuie sur Packer et Terraform.
Dans un premier temps, Packer est est utilisé pour déployer l’image servant de base à notre infrastructure. Les tâches accomplies par Packer sont les suivantes :
- Récupérer le tar.gz de Splunk
- Le dézipper
- Le placer dans un répertoire
- Créer un user Splunk
- Créer un groupe splunk Unix
- Modifier les propriétés du répertoire de façon à ce qu’il appartienne à l’utilisateur Splunk
Une fois qu’on dispose de cette image statique, on l’utilise pour déployer les différents éléments de l’infrastructure avec Terraform : searchhead, indexeur, etc. Ensuite,il ne reste plus qu’à modifier certains fichiers dans le searchead ou l’indexeur, en fonction de ses besoins. Utiliser une image permet non seulement de gagner un temps précieux, mais également de fiabiliser la base de départ en la “figeant”. On peut par exemple prévoir une image par version de Splunk.
Dans cette séquence d’automatisation, la complexité vient surtout de la nécessité d’éditer les fichiers de configuration pour déclarer les IP de chaque élément. D’où l’intérêt d’utiliser Terraform, qui récupère les propriétés des objets qu’il génère pour les réinjecter dans un autre. Terraform va ainsi construire chacun des objets, et dispatcher les IP correspondantes dans le bon ordre. Par exemple, l’IP du master est placée dans le fichier de configuration des indexeurs, qui seront démarrés après le master, dont ils sont dépendants. Terraform, par défaut, choisit l’ordre des actions nécessaires pour répondre à l’état décrit : attention à ne pas faire de boucle de dépendance; pour éviter cela, il suffit de fixer un élément, par exemple l’IP du déploiement serveur.
Dans notre solution d’automatisation, Terraform permet donc de déployer l’ensemble de l’infrastructure Splunk sur AWS, ainsi qu’un loadbalancer et un autoscaling group. L’autoscaling group permet d’adapter le nombre de serveurs à la charge : on définit par exemple un minimum 2 serveurs, un maximum de 10 serveurs, et une moyenne de 5. Avec l’autoscaling group, AWS s’adapte en fonction de la charge, et démarre d’autres instances si besoin.
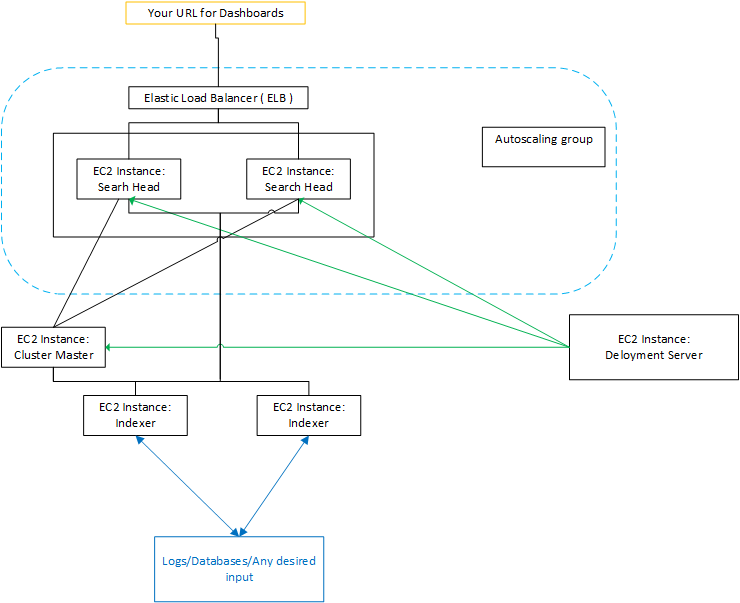
Concrètement, cette solution d’automatisation permet de déployer une infrastructure Splunk (searchhead, indexeurs, objets…) sur AWS en moins de 5mn : c’est la base indispensable pour commencer à travailler avec Splunk sur AWS. Potentiellement, le même déploiement manuel pourrait prendre plusieurs heures.
Retrouvez le Template Terraform Splunk sur GitHub.

Commentaires :
A lire également sur le sujet :






