
Start-Up : Docker Swarm et Container as a Service
Dans le cadre de notre série d’articles sur les outils IT pour les start-up, et après avoir abordé le déploiement de la software factory avec Ansible et le DevOps, nous vous proposons aujourd’hui de découvrir Docker. Comment déployer un cluster Docker ? Comment et pourquoi faire du Container as a Service avec Docker Swarm ?
Dans cet article, nous aborderons la mise en place du cluster Docker Swarm sur deux environnements distincts, production et non production, nous verrons en quoi cela est utile, et quelles contraintes sont amenées.
Dans un deuxième article, nous parlerons des problématiques de gestion des logs, du monitoring, du backup et du loadbalancing.
Limiter le coût d’infrastructure des VM
Si on repart du cas d’usage de la start-up, on constate que le manque de moyens limite nécessairement le nombre de serveurs. Pourtant, la start-up a bien besoin de plusieurs environnements : développement, UAT, préproduction, production…ce qui implique plusieurs instances de l’application. Si la start-up fait le choix de machines virtuelles, alors il faut prévoir une VM par environnement. Non seulement prévoir autant de VM a un coût, mais cela peut vite devenir difficile à gérer.
C’est ici que Docker entre en jeu : l’outil permet de mutualiser un certain nombre d’environnements de son application sur la même VM.
Au lieu d’avoir cinq machines virtuelles ou plus, il est possible d’avoir tous les environnements sur une seule VM, puisqu’ils sont tous dans des conteneurs séparés. Chaque environnement et ses dépendances (librairies, version de Python, Java, PHP…) est isolé de l’autre. Ensuite, il est possible de créer des environnements à la volée sur la même VM ou sur le même cluster de VM. C’est un gros avantage économique.

Répondre aux enjeux du DevOps
L’autre avantage de Docker, c’est qu’il répond parfaitement aux impératifs d’intégration et de déploiement continus : le Docker buildé dès le départ est le même que celui déployé en production, seules les variables et fichier de configuration changent. Comme c’est la même image de conteneur, avec les mêmes binaires et dépendances, on réduit fortement les risques de rater une mise en production.
Cela incite également les développeurs comme les Ops à penser automatisation et industrialisation. L’image du conteneur est générée à partir d’un Dockerfile. C’est une sorte de script qui permet d’installer l’application, ses dépendances, et pré-configurer le futur conteneur. L’image générée pourra être instanciée très facilement sans tout réinstaller.
Pour une start-up, il est important de prendre dès le départ les bons réflexes devops : s’assurer qu’on a un seul pipeline déploiement en est un.
Automatiser et industrialiser ce pipeline en est un autre, essentiel pour fiabiliser rapidement les développements, ainsi que pour réduire la charge de run sur l’Ops (car il est souvent seul dans une start-up). Il pourra mettre à profit le temps gagné pour améliorer régulièrement l’industrialisation et l’automatisation des outils, de l’infrastructure, et du pipeline, avec l’aide des développeurs.
Pourquoi choisir Swarm
Nous avons choisi Swarm mais il existe d’autres alternatives sur le marché, notamment Kubernetes et Mesos. Cependant, ces deux derniers sont presque trop complexes pour le besoin à adresser, et dans ce cas on se prive de l’accès direct à l’API Docker, et donc de tout l’écosystème très riche de Docker. Il serait possible de développer les intégrations manquantes pour communiquer avec leur API, mais c’est un contretemps non négligeable dans le cas d’une start-up. Le choix le plus évident, le plus simple à mettre en oeuvre est alors Swarm.

Docker Swarm
Comment fonctionne Swarm
Swarm est un scheduler de ressources, c’est-à-dire un service qui a une vue sur toutes les instances (serveurs) Docker, et qui est le point d’entrée universel vers tous ces nœuds. Par exemple, c’est Swarm qui se charge d’instancier un conteneur sur le cluster. Swarm choisit l’emplacement de ses déploiements en fonction de certaines règles, filtres ou stratégies de déploiement. Par exemple, on peut spécifier les besoins d’un container à un certain niveau de CPU et de RAM; Swarm effectuera son choix d’hôte Docker de façon à répondre à ces conditions.
Autre possibilité offerte par Swarm, celle de tagger les hôtes Docker avec des labels : un label SSD permettra à Swarm d’identifier les hôtes plus performants pour déployer un Docker base de données. Les labels peuvent aussi être utilisés pour identifier des régions.
Avec la dernière version de Docker (1.12, voir les détails ci-dessous), Swarm est maintenant totalement intégré au Docker Engine en tant que Swarm Mode. Il est activable à la volée et permet de monter très facilement un cluster Swarm de production. C’est une très grosse évolution qui simplifie énormément la mise en place de Swarm : plus de PKI à gérer soi-même, plus besoin de cluster KV tels que Consul ou Etcd.
DockerCon 2016 – Introduction à Docker 1.12 et démo
Stratégies de déploiement Docker
On distinguera trois stratégies de déploiement :
- Déployer sur un premier hôte jusqu’à ce qu’il soit plein, puis déployer sur le second hôte, etc. (binpack)

- Distribuer aléatoirement les nouveaux conteneurs sur les différents noeuds, de façon à laisser de la marge et ne pas les saturer (spread)
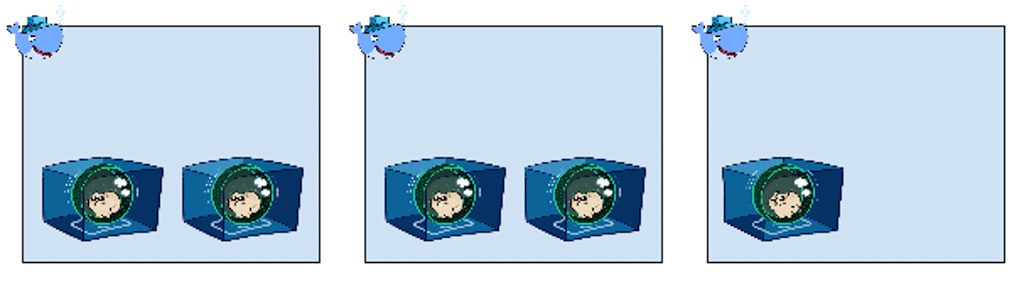
- Aléatoire (random)
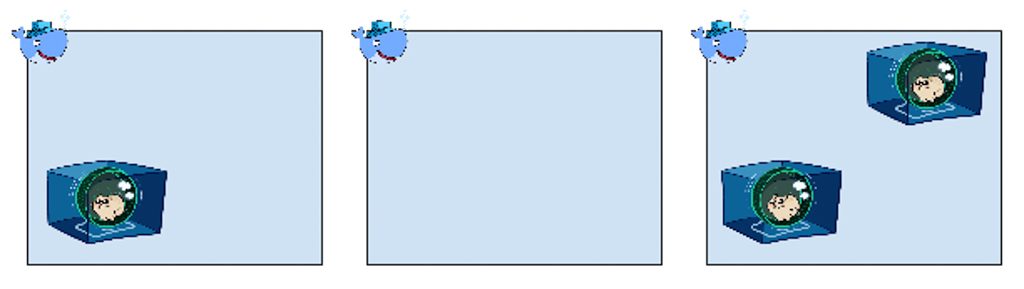
On choisira la stratégie en fonction de ses besoins, stratégie qui sera exécutée par Swarm de façon à ce que les déploiements se passent le mieux possible.
Par exemple, en production, si on plafonne les ressources allouées à chaque conteneur pour éviter tout débordement de consommation sur un autre conteneur, on peut choisir “binpack” pour remplir au maximum chaque hôte et gérer finement le capacity planning et les coûts. Ou choisir “spread” si les conteneurs vont consommer les ressources en même temps, et si on veut réduire l’impact de la perte d’une VM en répartissant les instances d’un service sur plusieurs VMs.
Swarm et le service Docker
Récemment, Docker a introduit la notion de “service”. Un service est composé de un ou plusieurs conteneur(s) qui forment un service. Un service peut aussi être composé de réseaux Docker et de volumes. Un service peut être déployé via Docker Compose ou Ansible 2.1 avec le module “docker_service”, ou la commande Docker depuis la version 1.12.
Prenons le cas d’un service WordPress, composé d’un conteneur WordPress, et d’un conteneur pour sa base MySQL. Chaque micro-service (appelé task) peut être scalé indépendamment. Par exemple, on peut demander à Swarm de déployer 3 instances de la task WordPress et une seule instance MySQL.
Le cluster sait aussi s’auto-réparer : si Swarm détecte la perte d’un noeud Docker, il va automatiquement rescheduler les “tasks” perdues sur les autres noeuds du cluster, en fonction de de la disponibilité des ressources, et des contraintes données par l’utilisateur. Le load-balancing interne sera également automatiquement mis à jour.
Il faut tout de même prêter attention aux tasks nécessitant des volumes de données persistantes. En effet, le rescheduling de tasks permet uniquement d’instancier ailleurs un conteneur, mais les volumes ne sont pas gérés par défaut. Par exemple, sur la base Mysql est déplacée vers un autre noeud, ses données ne suivront pas.
Dans ce cas, il est recommandé d’utiliser une des solutions suivantes :
- Des volumes sur NFS partagés par tous les noeuds du cluster
- Des volumes sur GlusterFS
- Des volumes sur baie NAS ou SAN
- Utiliser les solutions de stockage partagé des Cloud providers
- Des bases de données qui gèrent elles-même la réplication
Il existe de nombreux plugins Docker Volume qui permettent de gérer ces solutions de manière intégrée et transparente, sans configuration système pour certains, et donc de résoudre la problématique des données persistantes lors du rescheduling de task.
Continuous deployment
Le déploiement d’une nouvelle version n’est jamais une chose facile sur un cluster. Il faut éviter les downtimes en production, déployer l’application sur tous les nœuds, pas forcément en même temps, mais rapidement. Il est maintenant possible de gérer simplement les déploiements de nouvelles version d’une task (et donc de l’application) grâce à la nouvelle version de Docker 1.12.
La commande “docker swarm update“ permet de déclencher une “rolling update” d’une task. On peut paramétrer le nombre de tasks à mettre à jour en même temps, et le délai entre chaque lot de mises à jour. Encore une fois le loadbalancer interne à Docker 1.12 est mis à jour en temps réel.
On ne parle pas de Blue / Green Deployment ni de Canary release, mais c’est une fonctionnalité déjà très avancée, le tout, en toute simplicité. Une startup a rarement le temps et l’argent pour monter une solution maison capable de faire la même chose.
Les conditions d’une infrastructure résiliente
Quels sont les besoins en résilience ? On a vu que Swarm est capable de gérer la perte d’un ou plusieurs noeud(s) du cluster.
Cependant, cela ne permet pas de gérer la perte d’un datacenter.
Il est toujours conseillé de déployer une infrastructure et sa résilience sur plusieurs datacenters ou zones de disponibilité afin de prévoir une panne majeure. Cependant, distribuer une infrastructure sur plusieurs datacenters peut considérablement complexifier une infrastructure. Par exemple, la latence entre 2 datacenters ne permet pas de répliquer une base de données de manière synchrone sans impacter lourdement ses performances. Il faudra donc bien réfléchir aux impacts d’une telle architecture.
Pour une start-up, la continuité d’activité en cas de panne majeure de datacenter n’est pas toujours indispensable, du moins au début. Avoir un cluster, et une architecture applicative active/active et scalable permet déjà de de se sortir de beaucoup de pannes.
Scalabilité
Toute start-up est à la recherche du succès, ou du fameux buzz qui lui permettra de décoller. Ce buzz, s’il arrive, n’est pas toujours prévisible, et si au contraire il l’est, il faut être prêt. Vous avez certainement déjà de tenté de vous connecter au site d’une startup présentée en prime time à la télévision: en général, il est indisponible. Le pic de trafic n’a pas été suffisamment anticipé…
Cette situation peut être dramatique pour une start-up : les opportunités de se faire connaître ne se représentent pas toujours, et l’image de la société en ressort également ternie.
Afin d’anticiper au mieux ce type d’événement, il faut être capable de scaler rapidement l’infrastructure afin de surprovisionner à l’avance les resources. Cela suppose de pouvoir instancier de nouveaux serveurs rapidement et de manière industrielle, mais également déployer les nouvelles instances de l’application.
C’est ici que Swarm et les services Docker interviennent avantageusement grâce à la dernière version de Docker. Il est maintenant très facile d’ajouter de nouveaux nœuds Docker Engine au cluster Swarm, et ensuite de demander à Swarm d’augmenter le nombre d’instances (replicas) d’une ou plusieurs task(s) d’un service. À l’inverse, supprimer les ressources non utilisées est tout aussi important pour optimiser les coûts.
La scalabilité automatique en fonction de la charge n’est pas forcément une priorité car elle demande pas mal de temps pour être mise en oeuvre et une bonne maturité technique. Ce qui n’est pas évident pour une start-up qui court après le temps et l’argent. La priorité, c’est de pouvoir anticiper et gérer les pic de charges.
Architecture Swarm
Au niveau architecture, on recommandera tout de même comme bonne pratique d’avoir plusieurs clusters Swarm pour gérer les différents environnements : par exemple, un pour la production, et un pour la non production. Ils doivent doit être déployés de façon iso, au risque d’avoir de mauvaises surprises au moment de passer en production.
Avec ces deux environnements, une mise à jour Docker peut être testée au préalable : si tout se passe bien, elle peut alors être déployée en production.
Cette séparation des clusters permet aussi de faire des tests de performance sur l’un des environnements, sans impacter celui de production.

Sécurisation de Swarm
Toutes les communications entre les noeuds Swarm Manager, les noeuds Docker Engine, et les clients Docker doivent être chiffrées et authentifiées par protocole SSL afin d’éviter toute prise de contrôle pirate sur le cluster.
Grâce à la nouvelle version 1.12 de Docker Engine et son Swarm mode, la gestion de cette PKI (Public Key Infrastructure) SSL, de la création des certificats et leur renouvellement est totalement intégrée et automatique. C’est une simplification est vraiment bienvenue, et permet d’instancier sans effort ni orchestration complexe d’un nouveau worker Docker dans le cluster.

Source : Laurel
Maintenance Docker
Comme pour tous les outils récents et en évolution régulière, la principale contrainte est de gérer les mises à jour. Mettre à jour Docker demande de couper tous les conteneurs sur la machine à updater, ce qui entraîne une interruption de service sur le nœud. C’est donc une tâche qui demande un peu de planification : il faut fonctionner en mode clusterisé et intervenir sur le loadbalancer pour répartir la charge sur les noeuds encore actifs.
A noter que la version 1.11 de Docker apporte les fondations techniques pour permettre, bientôt, de mettre à jour le service Docker “Containerd” sans redémarrer les conteneurs instanciées “runC”.

Pour faciliter les maintenances, il est vivement conseillé d’utiliser les services Docker. En effet, on peut maintenant déclarer un nœud comme étant en maintenance (version 1.12). Ce nœud ne recevra plus de nouvelles tasks, et les tasks existantes seront stoppées et re-programmées sur les autre nœuds du cluster. Le load balancer interne sera également mis à jour automatiquement. On pourra donc très facilement intervenir sur un nœud Docker et éviter les downtimes.
Conclusion
Dans cette partie, nous avons vu en quoi la conteneurisation et le Dockerfile peuvent inciter dès le départ à développer et déployer des applications dans un pipeline industrialisé. Nous avons expliqué le choix de Swarm comme outil de gestion de cluster Docker pour sa simplicité d’implémentation et d’utilisation. Enfin, nous avons abordé le déploiement, les dependances, le besoin d’avoir plusieurs cluster Swarm sécurisés, et sa maintenance.
Dans un prochain article, nous aborderons la gestion des logs, du monitoring, du backup et du loadbalancing.
Automatisation, Big Data, DevOps, Désautomatisation… tous ces sujets seront abordés lors du TIAD 2016. Rejoignez-nous !

Commentaires :
A lire également sur le sujet :






