
Itinéraire de consultant : découvrez les coulisses d’un projet Google Serverless
Quel est le quotidien de nos consultants en mission ? Quels sont les challenges techniques qu’ils doivent relever et quelles solutions sont apportées ? Derrière une mise en production réussie, un déploiement ou un Proof of Concept, il y a des consultants, une équipe, des technologies et beaucoup d’expertise et d’intelligence collective ! Cette série d’articles vise à vous dévoiler l’envers du décor, à travers le témoignage de nos consultants.
 Comment collecter un large volume de données venant alimenter un Datalake, tout en maîtrisant les coûts et en assurant la scalabilité du système sans contraintes Ops ? Camille Tolsa, Ingénieur logiciel Google Cloud, a ainsi participé à un projet entièrement basé sur les solutions Serverless de Google Cloud Platform. Il témoigne ici de l’évolution de ce projet, de sa montée en compétence sur la partie Serverless, et de la collaboration avec la communauté Google Cloud et Apache Beam pour faire avancer le projet.
Comment collecter un large volume de données venant alimenter un Datalake, tout en maîtrisant les coûts et en assurant la scalabilité du système sans contraintes Ops ? Camille Tolsa, Ingénieur logiciel Google Cloud, a ainsi participé à un projet entièrement basé sur les solutions Serverless de Google Cloud Platform. Il témoigne ici de l’évolution de ce projet, de sa montée en compétence sur la partie Serverless, et de la collaboration avec la communauté Google Cloud et Apache Beam pour faire avancer le projet.
Peux-tu décrire le contexte du projet Serverless sur lequel tu travailles ?
Le Datalake a pour objectif de collecter des données métiers issues de différents capteurs sur l’ensemble de la planète. Toutes ces données sont insérées dans BigQuery pour ensuite construire des chaînes de BI ou bien les croiser pour en extraire une plus value : analyse, optimisation de coûts, prévention des pannes…
Quels types de données sont collectées ?
Au début du projet, il ne s’agissait que de données métiers issues de capteurs IoT, mais nous récupérons maintenant tous types de données de tous pays, par exemple des logs applicatifs. L’idée est de centraliser l’ensemble des données dans un seul silo, BigQuery, afin d’uniformiser l’accès aux données, et de contrôler cet accès. BigQuery permet d’optimiser le coût de stockage des données, les laisser dans des bases Oracle serait plus coûteux.
Quels outils Serverless utilises-tu ?
Initialement nous n’utilisions que Airflow pour l’ordonnancement des jobs, et Python pour la programmation des traitements qui démarraient des jobs Dataflow, pour ensuite collecter les données, les traiter, les reformater avant l’insertion dans BigQuery. Nous sommes ensuite allés beaucoup plus loin sur la partie Serverless.
Qu’est-ce qui explique cette montée en puissance sur le Serverless ?
La demande du client était d’accroître la collecte de données en exploitant au maximum les outils Serverless de Google. Ces services permettent en effet de travailler sans ops et de rendre les développeurs autonomes sur les déploiements, la gestion des logs, les rollbacks, etc. C’est également une question de maîtrise des coûts : de nombreux services ne sont sollicités que deux fois par mois, et nous avons beaucoup d’applications qui sont peu sollicitées, qui servent régulièrement, mais qui n’ont pas besoin d’être up 24/24.
Quels services ont été choisis pour traiter le volume croissant de données ?
Nous avons choisi App Engine et DataFlow pour nous abstraire des contraintes d’échelle : les fichiers sont envoyés, le code est exécuté… et DataFlow gère le démarrage d’une, cent ou mille VM en fonction du besoin. Certains jobs peuvent ainsi faire démarrer 500 VM pour traiter les fichiers. C’est du traitement de données relativement basique, mais qui pose beaucoup de contraintes de volumes. Nous avons 14 000 datasets sur toute la société, et 150 sur le Datalake (des ensemble de tables, comme une base de données SQL), et notre plus volumineuse source de données représente 1 To/mois. En tout, nous avons 50 sources de données, et chaque job lancé quotidiennement traite entre 30 et 60 gigas de données.
Quels autres services Google sont utilisés ?
Presque tous les services Google à l’exception de Dataproc et Dataprep, qui sont sortis après le développement de notre solution. Pour l’authentification, nous utilisons IAP, Serverless également. Le Serverless est un écosystème très dynamique, en plein développement. Beaucoup de choses vont changer prochainement, notamment avec la fusion de AppEngine et AppEngine Flexible, ou la prochaine version de Big Query, dont nous testons actuellement une version Alpha. Il y a beaucoup de changements dans l’interface, et il est enfin possible de lancer de gros jobs depuis l’interface sans excéder les ressources.
Quels sont les traitements ?
Il s’agit de récupérer les fichiers, les dézipper, les normaliser, en fusionner certains, effectuer un contrôle de valeur, exclure certaines valeurs… quand les données sont propres, elles sont envoyées dans BigQuery. Tout ce traitement est automatisé avec un service AppEngine, Cron permettant la programmation de jobs, comme une crontab. Cron appelle des services à heures régulières pour vérifier si des données ont été reçues pour telle source ; si oui, un job dataflow est déclenché, il va lire les données, les traiter puis les insérer dans BigQuery.
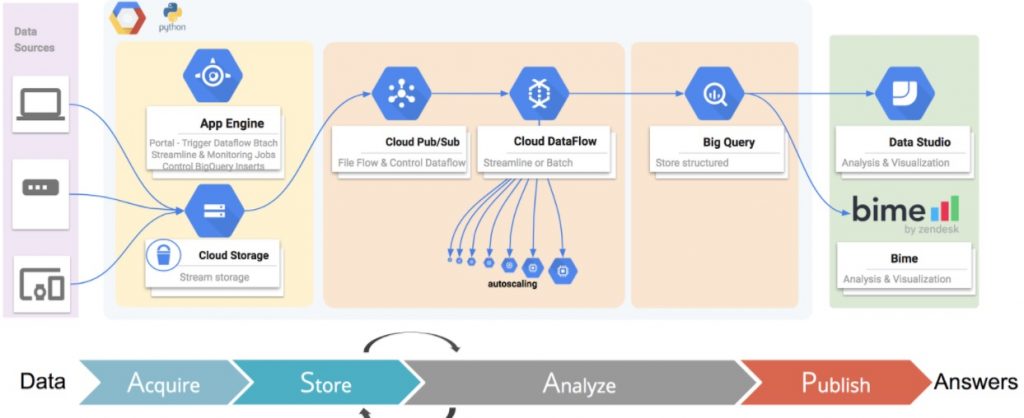
Comment l’application est devenue complètement Serverless ?
Dans un premier temps, nous avons recensé tous les flux de données présents dans l’application, puis nous avons réfléchi au découpage en services du workflow existant, et du workflow vers lequel tendre. L’objectif était donc d’utiliser le plus de services Serverless possible :
- Les sources de données sont décrites dans des fichiers de configuration stockées sur Datastore, base de données no sql serverless, ce qui nous évite d’avoir à se soucier du nombre de sources à gérer
- Le système réagit aux événements : un fichier déposé sur Google Storage génère une notification PubSub, à laquelle réagissent les services App Engine pour démarrer l’application et consommer le fichier. Tous les traitements sont ensuite réalisés en Serverless.
Nous ne traitons pas que le dépôt de fichiers : certains fichiers doivent être récupérés sur des SFTP, sur des sites HTTP, par l’appel d’API, ou dans des mails. Une fois encore, tout ici est traité de façon Serverless, à l’exception des fichiers sur SFTP. Nous sommes obligés d’exposer un serveur pour permettre aux filiales de déposer leurs fichiers. Pour les API, nous avons un job Dataflow qui se charge des appels.
Quels challenges as-tu rencontré ?
Quand j’ai démarré le projet, je n’avais jamais travaillé sur les technologies Serverless. Il fallait donc appréhender l’outil, se former, tout en travaillant sur un service en production, et régulièrement utilisé ! J’ai donc appris sur le tas, en me documentant et en échangeant avec des collègues connaissant le sujet. C’est un challenge d’apprendre tout en devant délivrer, mais au final l’usage de AppEngine est assez simple et on peut utiliser des schémas d’applications pré existants et écrire simplement des fichiers de configuration.
As-tu eu des difficultés liées à la jeunesse de l’écosystème Serverless ?
Ces technologies sont en effet très récentes et la documentation, quand elle existe, n’est pas forcément à jour. Et puis ces technologies évoluent en même temps que nous les utilisons, donc nous avons pris contact avec les équipes de Google Cloud et les développeurs du framework que nous utilisons, Apache Beam (équivalent Spark/Hadoop). Apache Beam permet d’exécuter un pipeline de données (consommation, traitement, exportation), et ensuite de passer à Dataflow, Hadoop ou Flink de façon totalement interopérable.
Quels sont les apports de la collaboration avec la communauté Apache Beam et ses développeurs ?
Quand nous avons besoin de certaines features qui n’existent pas dans le produit, on peut savoir rapidement si elles sont prévues dans la roadmap et à quelle échéance. En fonction, nous pouvons soit contribuer directement, soit développer les features dont nous avons besoin en interne. Être en contact régulier avec les product managers de BigQuery, DataFlow, AppEngine et Apache Beam nous permet donc de connaître les roadmap, d’obtenir des accès Alpha sur les nouveautés… nos besoins sont très nouveaux, nous essayons donc d’être à la pointe sur ces sujets. Et pour cela, il faut être entouré, et collaborer avec la communauté. C’est un échange très intéressant, j’apprécie de pouvoir discuter technique avec des développeurs à l’autre bout de la planète, contribuer, découvrir certaines fonctionnalités cachées, les tester, reporter des bugs sur leur Jira, échanger sur leur Slack privé… bref, faire partie de la communauté. Chaque jour, je prends aussi le temps d’aider la communauté ApacheBeam et Google. Nous produisons du code, et beaucoup de gens rencontrent les mêmes problématiques que nous, et si nous ne pouvons pas partager le code, nous partageons nos bonnes pratiques.
Quel sont les bénéfices clients ?
Il n’y a plus de contraintes ops, le système est totalement scalable et les coûts sont optimisés par rapport à nos besoins réels en termes de consommation de données. Et, chose rare dans le monde de l’IT, nous pouvons à peu près tenir les délais de la roadmap. Le datalake a été conçu de façon à pouvoir ajouter facilement de nouvelles sources, via une configuration Json qui permet d’activer différentes options pour la source. Nous capitalisons sur le code créé.
Aujourd’hui où en est l’application ?
Nous travaillons surtout sur des améliorations qualitatives, et nous développons des plugin pour que les différentes Business unit puissent se connecter au Datalake, tout en gardant le contrôle du stockage de leur données : notre moteur gère uniquement l’orchestration. Nous travaillons également sur un système d’alerte pour détecter les erreurs et les anomalies de façon prédictive. Enfin, nous allons mettre en place un nouveau portail web, qui permettra de visualiser toutes les sources du Datalake et de faire des demandes d’accès ou d’ajout de source.

Nos projets vous intéressent ? Discutons-en !
Envoyez un petit mot à Olivia : olivia.blanchon@revolve.team
Chez D2SI, nous avons toujours exploré les nouvelles technos et méthodologies d’automatisation. Rejoignez nous et soyez au coeur de cet éco-système avec D2SI !
Commentaires :
A lire également sur le sujet :






