
Tutoriel Serverless – 3 : Automatiser le reporting du Patch Management

Comment automatiser le patch management et notamment la gestion des redémarrages et des vérifications de serveurs ? Dans les articles précédents, nous avons vu le cas d’une infrastructure AWS avec EC2 System Manager, puis le détail de l’utilisation d’EC2 Systems Manager, de Jenkins, et la modification des “documents” Amazon avec l’implémentation des scripts. Dans cet article, nous allons voir la partie reporting du patch management, de la création de fichiers de log par nos scripts jusqu’à l’implémentation de ces fichiers de logs dans l’outils de dashboard google DataStudio.
Reporting : création des fichiers de log
Des exports “CSV” par instance sont effectués afin de connaître :
- Les mises à jour présentes sur l’instance, avant l’installation des mises à jour
- Les mises à jour installées sur l’instance après installation des dernières mises à jour
- Un comparatif entre le fichier avant mise à jour de l’instance et celui après mise à jour de l’instance. Ce qui donne un exports des nouvelles mises à jours installés sur l’instance
- Les mises à jour en échec, l’inventaire des logiciels installés
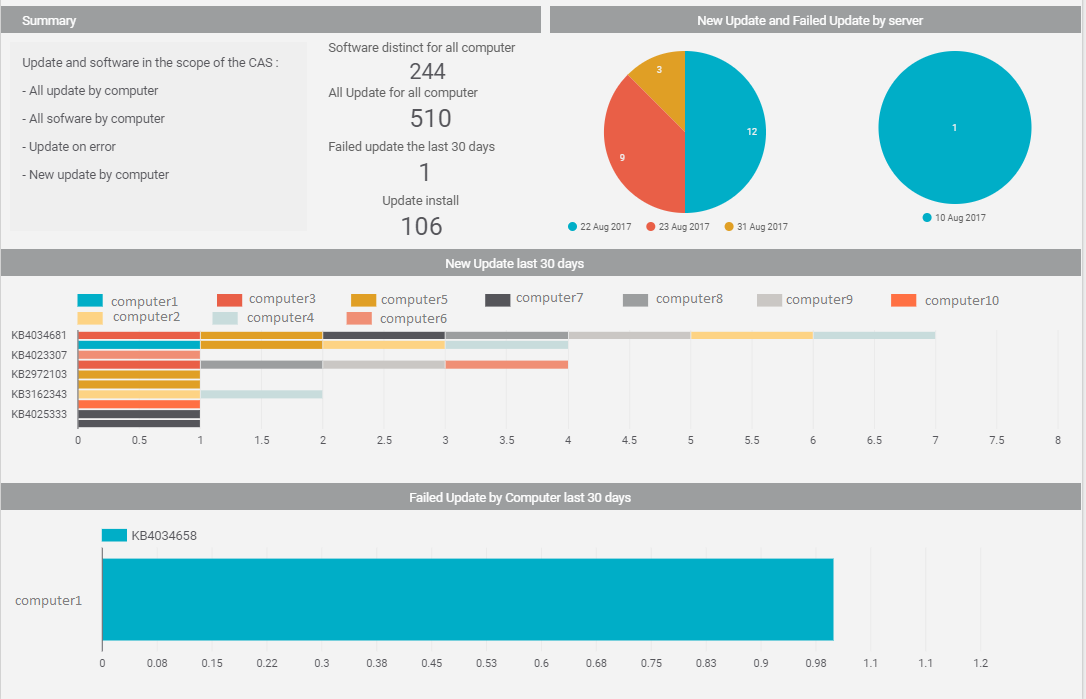
Exemple de fichier CSV : New Update Install

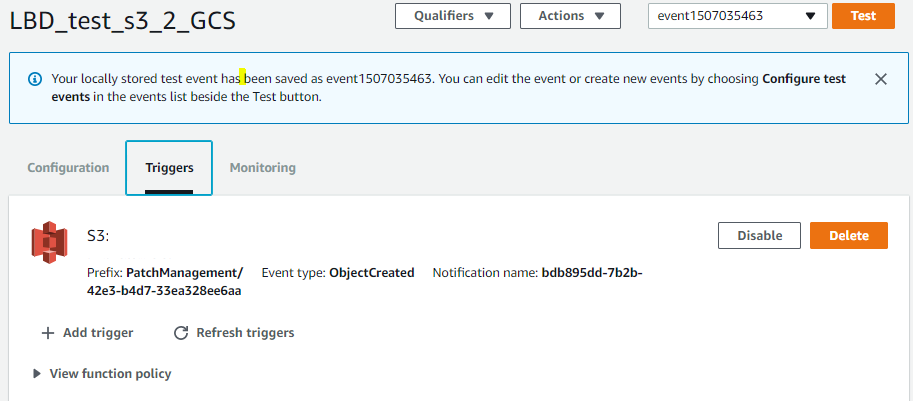
Lambda
Une fois les fichiers csv créés, une lambda se déclenche via un trigger mis en place sur le bucket ou les fichiers de log sont présents.
Cette lambda va transférer les fichiers de reporting entre le bucket S3 vers GCS.
Le trigger est configuré afin de transférer les fichiers vers GCS dès qu’un fichier est créé sur le bucket.
Exploitation des fichiers de log
Les fichiers de log sont des fichiers CSV, stockés dans S3. Ceux-ci seront importés sur un Datalake (BigQuery), puis visualisés dans un dashboard (Datastudio) afin de créer les reportings de :
- mise à jours des instances,
- logiciels installés,
- mises à jours en échec
- dernières mises à jours effectuées
Pour les instances qui sont éteintes, Jenkins démarre l’instance, lance l’execution des scripts, redémarre l’instance, et enfin l’éteint une fois que toutes les actions ont été effectuées. Cette démarche sera surtout utilisée hors production (instances éteintes le soir et WE).
Schéma fonctionnel du Patch Management serverless
Voici ci-dessous un schéma fonctionnel du Patch management
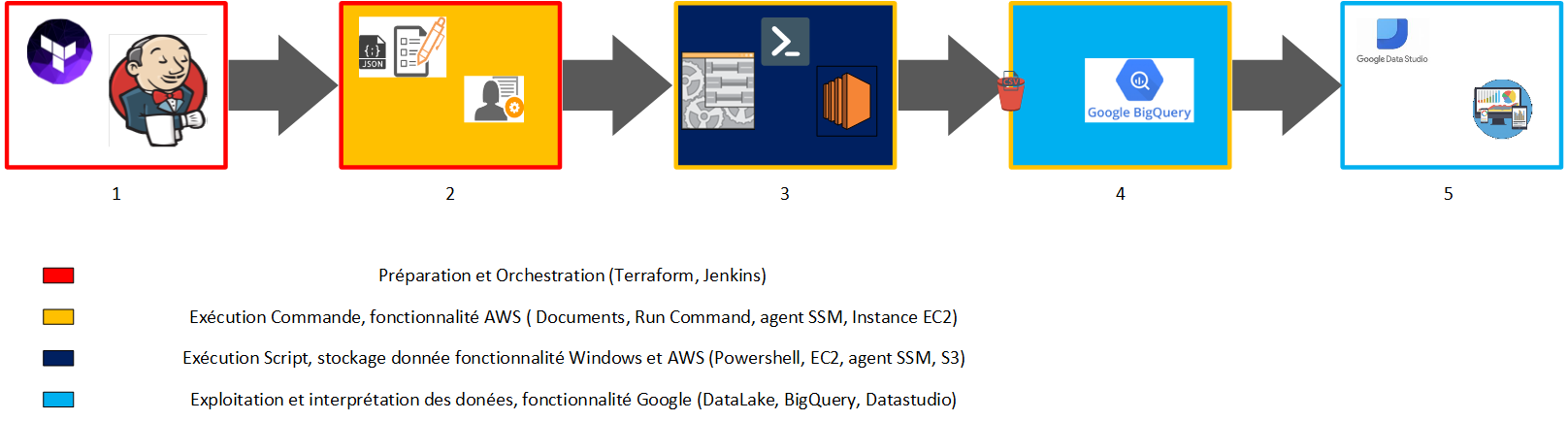
Cycle de vie Fonctionnel Patch Management :
- Utilisation de Terraform pour intégrer les documents “json” sur la platforme AWS. Utilisation de Jenkins pour orchestrer le lancement des documents via la fonctionnalité AWS “Run Command” durant les plages de maintenance
- L’agent SSM d’AWS récupère et convertit les documents “json” en script powershell pour la partie Windows et en Shell pour la partie Unix
- Exécution des scripts sur les instances. Récupération, installation des mises à jours de sécurité critiques. Création des différents fichiers de log. Export des reporting dans un bucket S3, vérification de la présence du fichier de reporting sur S3, avant suppression des fichiers sur l’instance
- Envoi des fichiers de reporting du bucket S3 dans une base Big Query via la datalake. Récupération des données sur de la table Big Query sur Data Studio. Exploitation et création de Dashboard pour l’analyse de l’installation des mises à jour
Schéma technique du Patch Management serverless
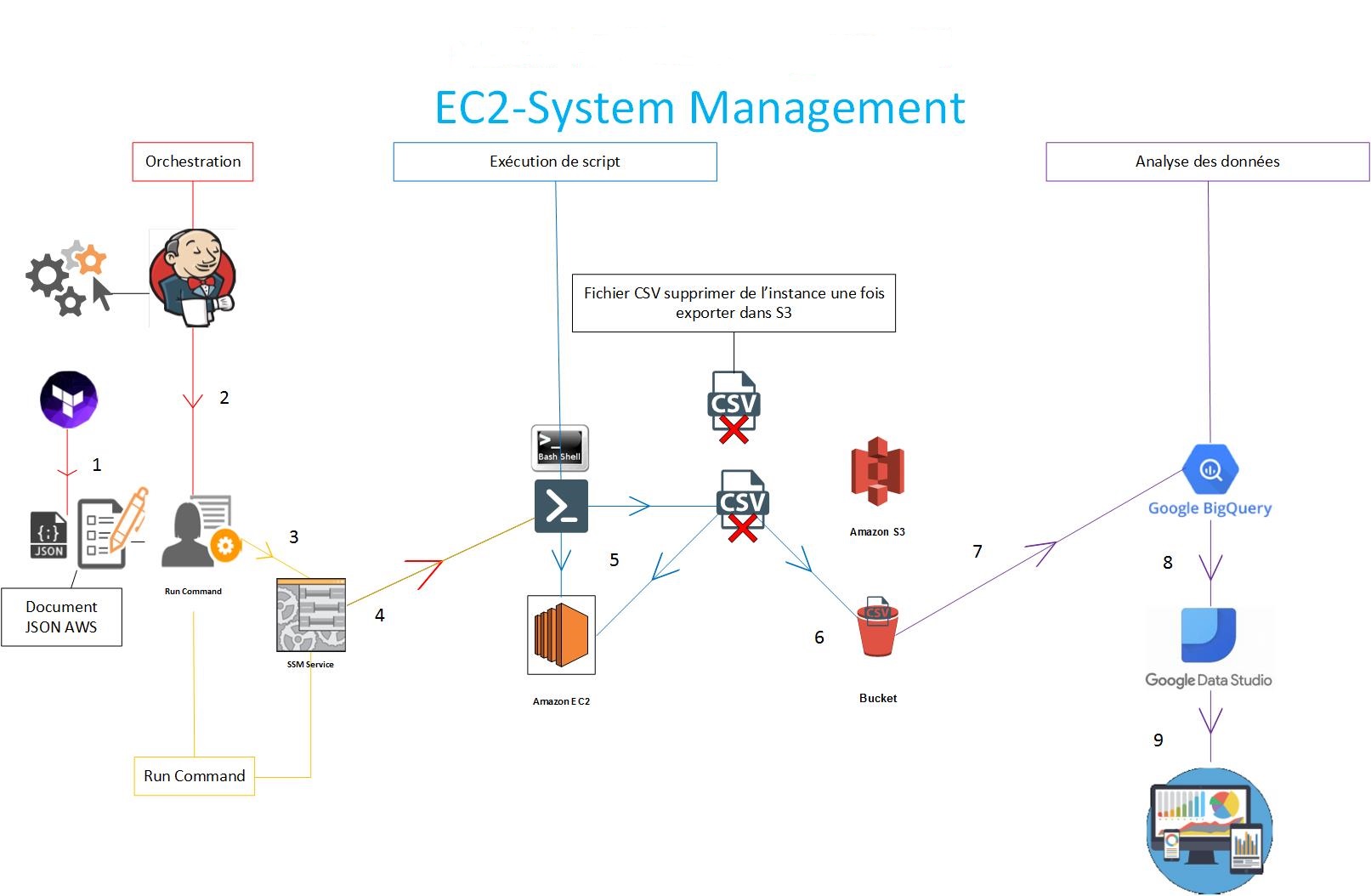
Cycle de vie Technique Patch Management :
- Utilisation de Terraform pour intégrer les documents “json” sur la platforme AWS
- Utilisation de Jenkins pour orchestrer le lancement des documents via la fonctionnalité AWS “Run Command” durant les plages de maintenance
- L’agent SSM d’AWS récupère et convertit les documents “json” en script powershell pour la partie Windows et en Shell pour la partie Unix
- Execution des scripts sur les instances
- Récupération, installation des mises à jours de sécurités critiques. Création des différents reporting
- Export des reporting dans un bucket S3, vérification de la présence du fichier de reporting sur S3, avant suppression des fichiers sur l’instance
- Envoi des fichiers de reporting du bucket S3 dans une base Big Query via le datalake
- Récupération des données sur de la table Big Query sur Data Studio
- Exploitation et création de Dashboard pour l’analyse de l’installation des mises à jour
Commentaires :
A lire également sur le sujet :






