
Configurer un fichier d’index par défaut sur les dossiers avec CloudFront

Cet article est la suite de vos aventures avec Jean-René et Sophie-Emmanuelle, si vous ne les avez pas lues, cliquez ici : configurer cloudfront en HTTPS avec S3 website.
C’est reparti. Vous pensiez en avoir fini avec Jean-René, mais ce matin il est revenu à la charge tout paniqué “les URLs ne fonctionnent plus, les URLs ne fonctionnent plus” répétait-il. Vous lui auriez volontiers proposé de passer au Nesquik plutôt qu’au café le matin, mais votre cheffe Sophie-Emmanuelle fit à cet instant irruption dans l’Open-space et soudain le problème de Jean-René avait un ingénieur pour investiguer. Oui je parle de vous.
Prenant alors votre rassurante voix d’ingénieur tout en chaussant vos nouvelles lunettes, vous proposez alors à Jean-René de vous montrer où est le problème. Ni une ni deux, Jean-René se jette sur le site de démo, clique une fois, deux fois, trois fois, et patatras, il se trouve devant le message “Access Denied”.
Ayant déjà réussi à transformer la fébrilité de Jean-René en satisfaction de celui-ci d’avoir montré qu’il avait raison, vous lui proposez de prendre congé le temps de regarder et corriger le souci.
Vous remontez donc le fil de la distribution Cloudfront, suivez les fichiers jusqu’au bucket S3, et vérifiez que l’identité d’accès à l’origine est correctement configurée: tout paraît correct. Le pire c’est que ce sont les pages d’index qui ne marchent pas, les images et autres éléments sont bien récupérés si on en possède l’URL. Et puis, soudain, vous avez une illumination, vous ajoutez “index.html” à la fin de l’URL que vous testiez et pouf ! La page s’affiche.
En fait, vous avez commis une erreur. Vous avez remplacé un “S3 website” en S3+Cloudfront mais vous avez oublié que Cloudfront n’est qu’un CDN. Il n’est pas capable de “trouver” tout seul le fichier index.html d’un dossier et ce, même si vous avez configuré un “index” dans la distribution : cela ne concerne que la racine de celle-ci. Pour CloudFront, les dossiers ça n’existe pas, c’est des URLs et c’est tout.
Heureusement vous avez trouvé un super article de blog qui explique tout ça, et c’est celui-ci #inception
Je vais vous présenter deux manières de faire du “directory url” avec CloudFront, c’est à dire d’exposer le fichier index.html d’un dossier lorsque l’internaute arrive sur une page http://monsite/dossier/
La première méthode nécessite de modifier votre distribution CloudFront, et la seconde sera peut être un peu moins chère à l’usage mais demandera à modifier la manière dont vous déployez votre site.
Mais tout d’abord, voici un petit paragraphe sur une méthode que je déconseille.
Méthode 0 – ce qu’il ne faut pas faire
Vous allez pouvoir trouver sur Internet, et peut être aussi dans le schéma d’architecture proposé par un de vos prestataires, la proposition suivante: puisque S3 website supporte les redirections sur index.html il suffirait de brancher l’origine de CloudFront au endpoint <bucket-name>.s3-website-<AWS-region>.amazonaws.com et le tour sera joué. Ça parait facile.
Pourquoi il ne faut pas le faire ? C’est assez simple. Quand on utilise CloudFront, on a envie en général de forcer les utilisateurs à accéder uniquement à notre site via CloudFront, cela permet, en outre, de mettre en place un WAF, mais aussi de maîtriser ses coûts de transfert depuis S3. Pour restreindre l’accès depuis votre bucket à CloudFront, il suffit de mettre en place une politique d’accès à l’origine. Or, pour que l’identité d’accès à l’origine fonctionne, il faut que CloudFront accède à votre bucket via le point d’accès REST de celui-ci <bucket-name>.s3-aws-<AWS-region>.amazonaws.com et non le point d’entré HTTP de S3 website <bucket-name>.s3-website-<AWS-region>.amazonaws.com.
Par conséquent, si vous configurez votre distribution CloudFront pour qu’elle pointe sur le point d’entrée s3 website <bucket-name>.s3-website-<AWS-region>.amazonaws.com, vous allez pour que cela fonctionne, être obligé de mettre votre bucket public, et donc les internautes pourront contourner le WAF via l’URL du endpoint s3-website.
Donc c’est une mauvaise idée. On pourrait même la ranger dans la catégorie des anti-patterns. Vous trouverez ci-dessous des meilleures idées.
Méthode 1 – Lambda@Edge
Le service de Lambda@Edge nous permettra d’exécuter des Lambdas depuis les “Edge location” de CloudFront, et ainsi, modifier les requêtes à la volée avec un morceau de code.
Voir la documentation.

Vous pouvez suivre le tutoriel d’AWS pour vous faire la main.
Créez une fonction NodeJS dans la région us-east-1, avec le code suivant :
'use strict';
exports.handler = (event, context, callback) => {
var request = event.Records[0].cf.request;
request.uri = request.uri.replace(/\/$/, '\/index.html');
return callback(null, request);
};
Note: si vous n’aimez pas le Javascript, tant pis pour vous, car les Lambda@Edge de CloudFront ne supportent que le NodeJS.
Cette lambda est très simple, donc elle ne coûtera que 50 millisecondes par exécution, ce qui est le minimum. En outre, CloudFront la mettra en cache, donc vous ne la paierez pas à chaque fois qu’un fichier sera accédé.
Publiez ensuite une version de votre lambda :

Ajoutez un trigger CloudFront, comme ceci :

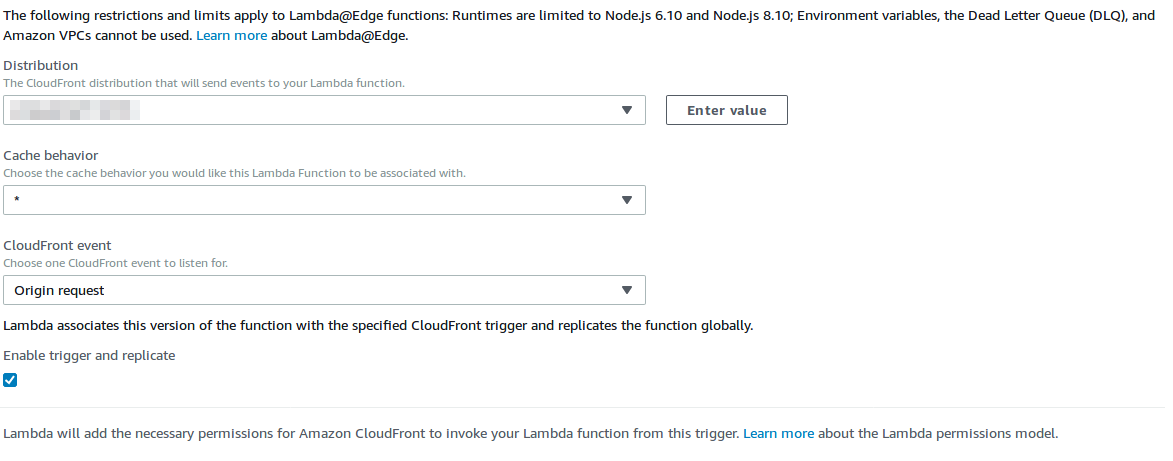
Et c’est fini ! Attention, les logs de votre lambda seront stockés en fonction de la Edge location accédée par les internautes visitant votre site.
Désormais, à chaque fois qu’une page finissant par “/” sera accédée, la lambda exposera à CloudFront le fichier “index.html”, de manière transparente pour les utilisateurs derrière le CDN.
Attention : vous ne pourrez pas supprimer votre Lambda, tant que celle-ci est associée à une EdgeLocation. Pour supprimer la Lambda, il vous faudra supprimer le trigger de la version de la Lambda, puis attendre la fin du déploiement pour supprimer votre fonction.
Méthode 2 – S3 objects
Vous le constaterez, même si les Lambdas@edge sont relativement peu coûteuses, vous allez quand même devoir payer du temps de Lambda “juste” pour faire des redirections d’URL, ce qui peut revenir assez cher sur le long terme si vous avez beaucoup de fichiers. Dans le cas d’usage précis du “directory URL”, on a en fait une autre option.
Si vous avez lu correctement la documentation de S3 (ou que vous avez la certification AWS Associate Architecte), vous savez que les dossiers, cela n’existe pas dans S3. S3 est un système de stockage clé/objet et vous pouvez mettre à peu près n’importe quoi comme clé, y compris le symbole slashe, c’est comme ça qu’on fait des dossiers. D’ailleurs, si vous listez un bucket en ligne de commande, vous recevrez tous les fichiers “à plat”, preuve que l’arborescence dans S3 ça n’existe pas.
Alors en quoi cela nous aide ? C’est très simple. Si vous pouvez mettre n’importe quoi comme clé, cela veut dire que vous pouvez créer un fichier avec la clé dossier/ contenant votre page d’index, et ainsi servir à Cloudfront un contenu sur cette URL. Alors oui, cela duplique les fichiers MAIS on économise de la Lambda. Faites le calcul du prix du stockage et vous verrez que vous serez probablement gagnant.
On se heurte quand même à un problème de taille, c’est qu’il n’est pas possible via AWSCLI de mettre des “/” à la fin des noms de clé, car celui-ci est conçu pour avoir à peu près la même logique que les commandes de copie unix : si on met un “/” à la fin de la destination, cela veut dire “conserve le nom du fichier et copie dans ce dossier”.
Donc il nous faut dégainer nos super pouvoirs de DEV pour faire ça. Et tant qu’à faire, puisqu’on a pas envie d’avoir à le gérer en local, si ça pouvait être fait par une lambda au moment du déploiement, ça pourrait être cool.
Créez donc une lambda NodeJS dans la même région que votre bucket, avec un rôle ayant la policy suivante:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::monbucket/*"
},
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Effect": "Allow",
"Resource": "arn:aws:logs:*:*:*"
}
]
}
Puis copiez-y le code :
'use strict';
exports.handler = (event, context, callback) => {
var AWS = require('aws-sdk');
var s3 = new AWS.S3();
var params = {
Bucket: event.Records[0].s3.bucket.name,
CopySource: "/" + event.Records[0].s3.bucket.name + "/" + event.Records[0].s3.object.key,
Key: event.Records[0].s3.object.key.replace(/index.html$/g, '')
};
s3.copyObject(params, function(err, data) {
if (err) {
console.log(err, err.stack);
}
});
};
Configurez à présent un trigger sur tous les fichiers terminant par “/index.html” poussés dans le bucket. En laissant le “/” au début du filtre, vous ne capturez pas le fichier racine.
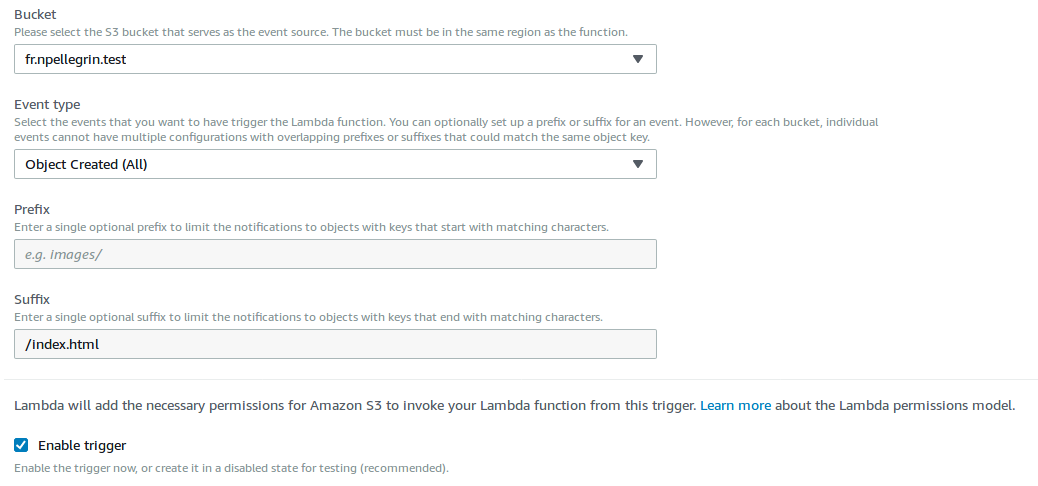
Et maintenant, essayez de pousser un fichier “dossier/index.html” dans votre bucket: vous allez avoir au bout de quelques secondes un autre fichier qui va apparaître appelé “dossier/” et ayant comme contenu votre fichier index.html.
Attention, vous ne verrez pas ce fichier supplémentaire en console, il faudra utiliser AWSCLI :
aws s3api list-objects --bucket monbucket
Conclusion
Les Lambda@Edge de CloudFront sont un outil puissant, qui vous permet de customiser la manière dont CloudFront répond à certaines requêtes. Il vous faudra cependant les écrire en NodeJS, et publier votre fonction à chaque fois.
Dans le cas d’usage de “directory URL”, vous avez la possibilité en trichant un peu sur le déploiement de vous en passer si vous ne souhaitez pas utiliser cette fonctionnalité. Néanmoins, gardez à l’esprit que cela duplique les fichiers, et que cela ne sera pas une solution robuste si vous souhaitez faire des redirections plus complexes ou ajouter des en-têtes HTTP.
Pour finir, parce que je suis un mec trop sympa, vous trouverez ci-dessous des exemples de code Terraform pour chaque méthode.
Fichiers Terraform – Méthode S3
Fichiers Terraform – Méthode Lambda
Commentaires :
A lire également sur le sujet :






