
Nos Apps Splunk basées sur AWS

Si nous intervenons sur la solution Splunk depuis quelques années maintenant, nous n’avions pas eu, jusqu’à présent, l’occasion de contribuer à la communauté à travers la publication d’Apps.
Il est vrai que les Apps Splunk que nous développons au fil de nos missions découlent généralement de cas d’utilisation définis par nos clients. Or, pour qu’une App soit publiable, sa portée doit être générique.
Quoiqu’il en soit, nous avons remédié à ce manque cet été en publiant une série d’Apps utilitaires que nous vous présentons ici.
Internal Billing
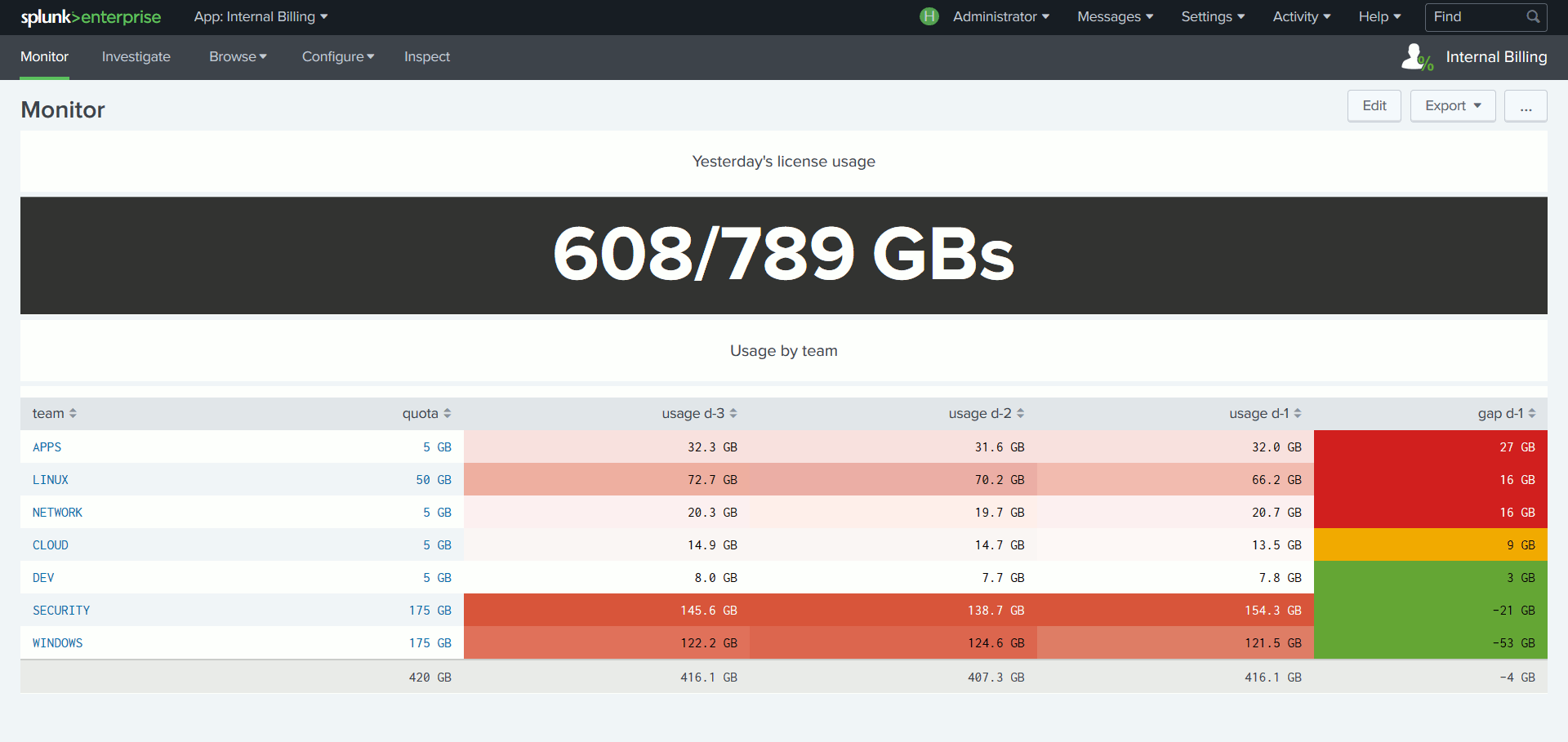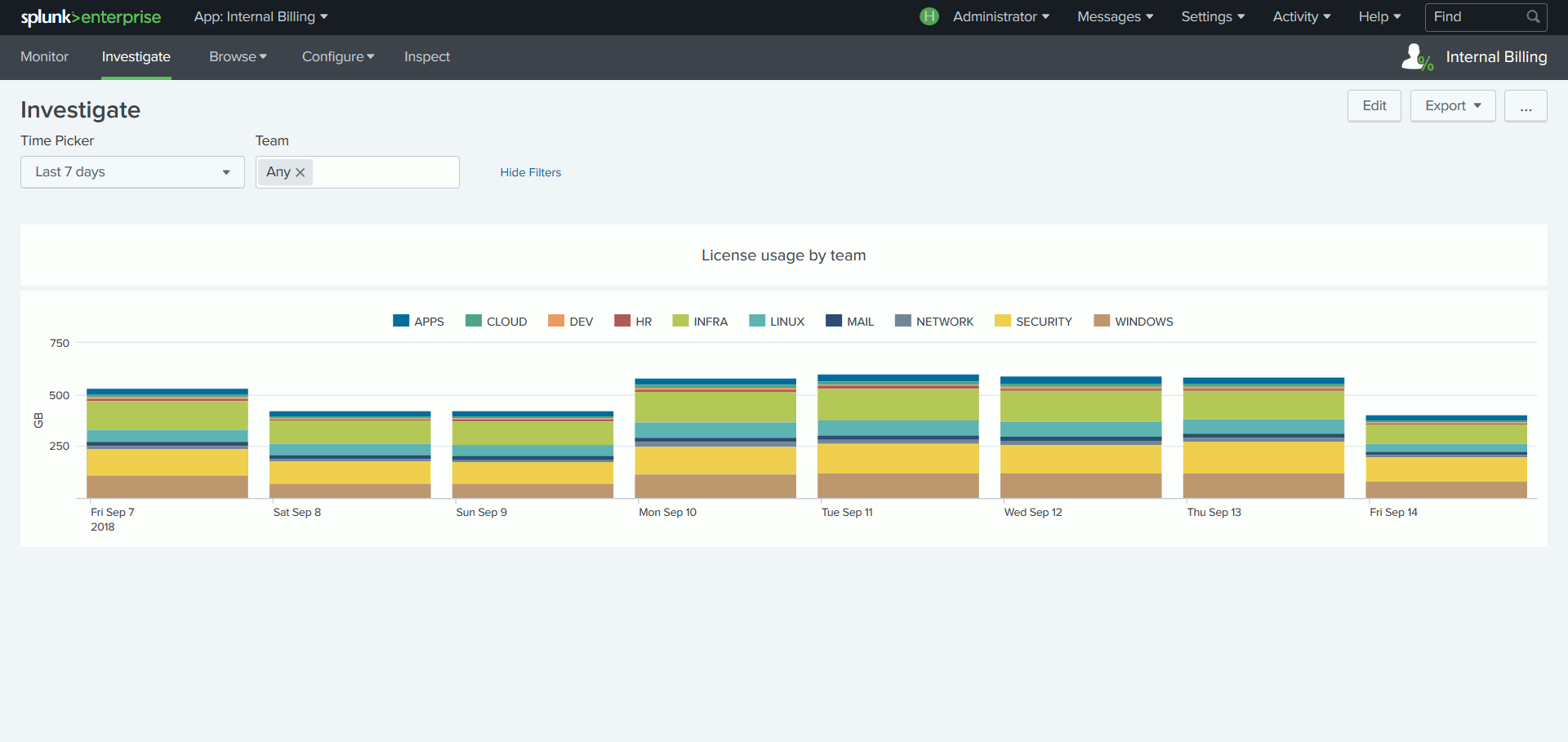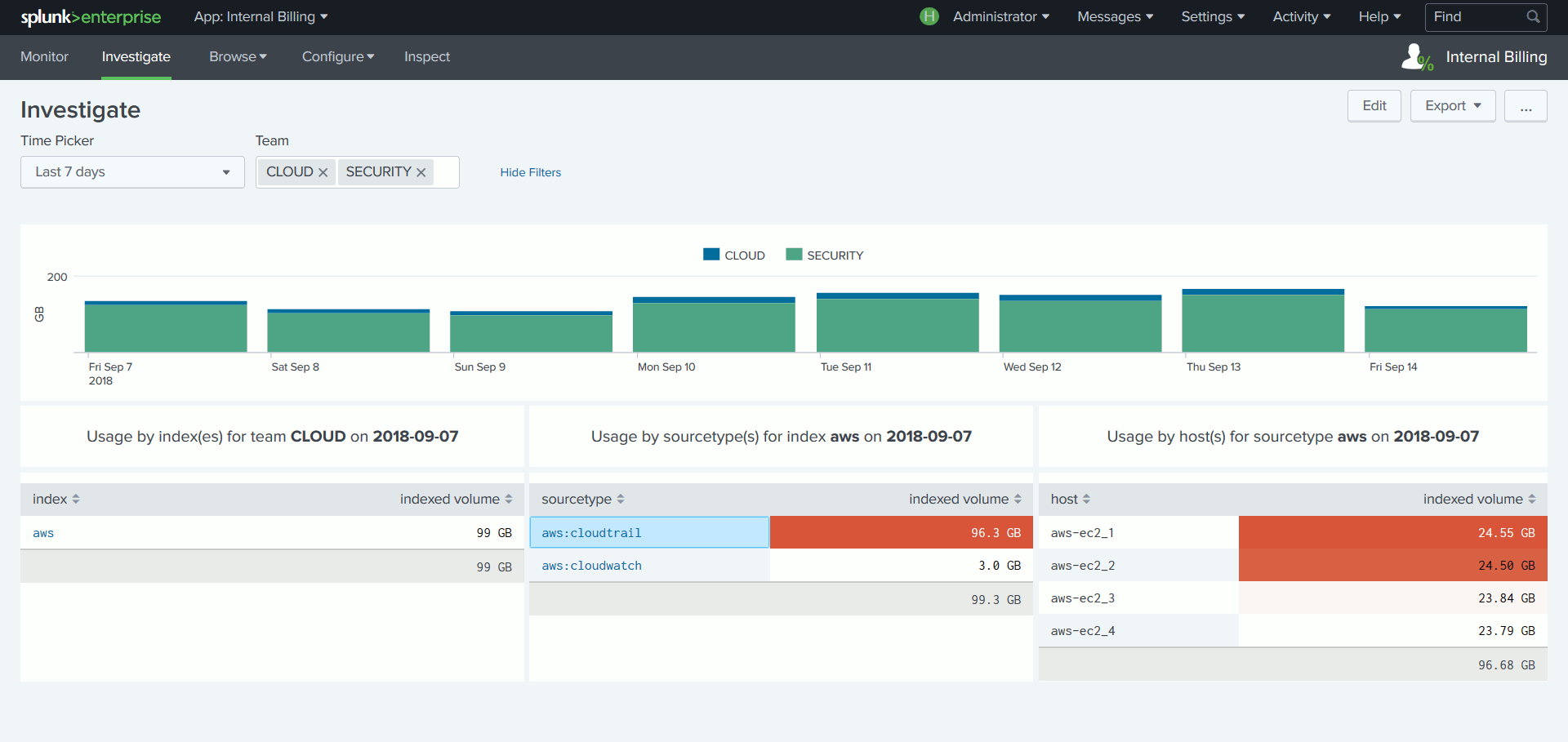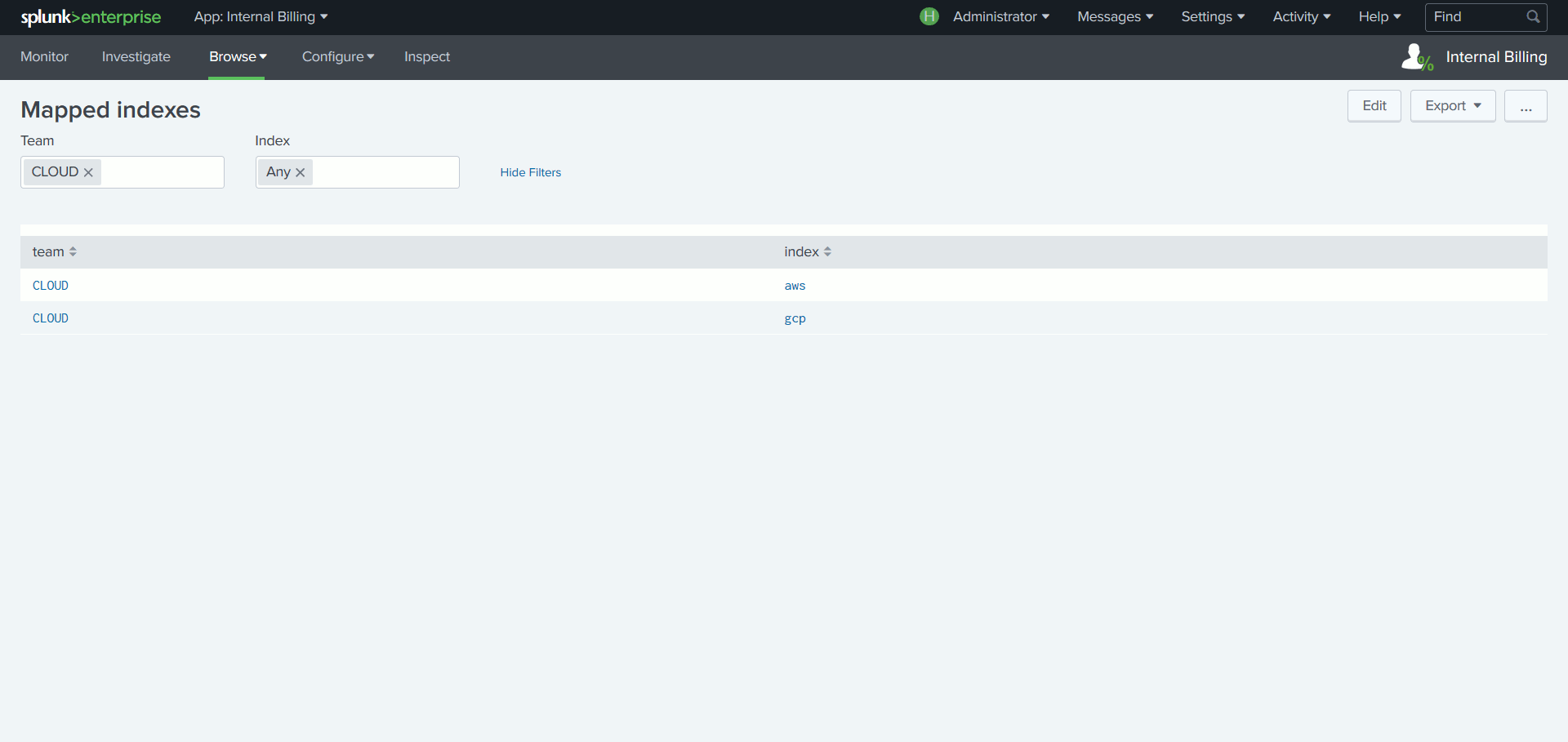
Le coût de la licence Splunk étant lié au volume de données indexé par jour, certains SI souhaitent refacturer à chaque équipe cliente de la plateforme la part de licence consommée. Or, s’il est facile d’obtenir le volume de données ingéré par index, Splunk n’a pas connaissance du lien entre un index et une équipe.
Pour corriger cela, l’App établit une correspondance entre une équipe et le ou les index à sa charge, tout en attribuant à chaque équipe un quota d’utilisation de la licence. Une suite de tableaux de bord basés sur cette intelligence facilite le suivi de la consommation de licence par équipe.
Index Usage
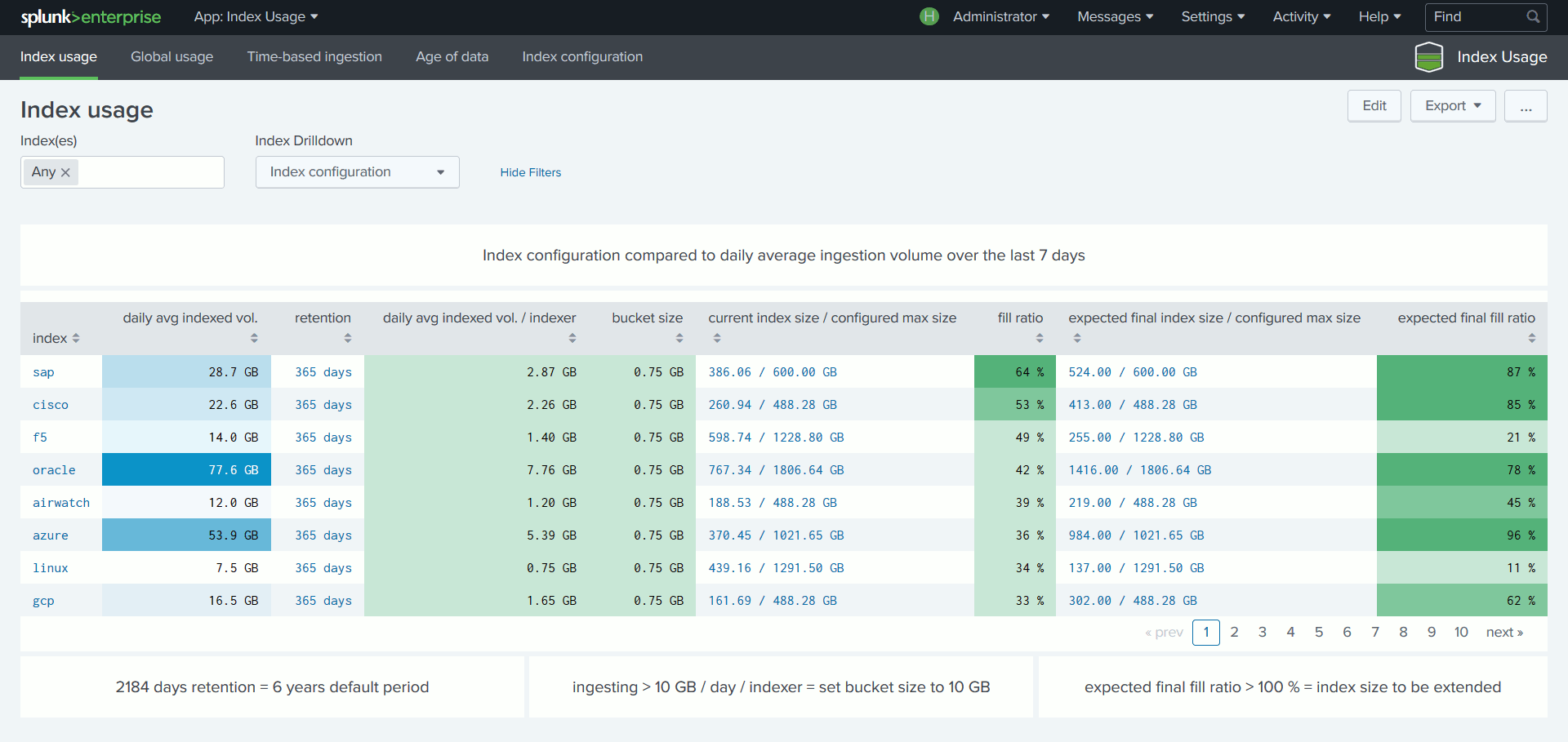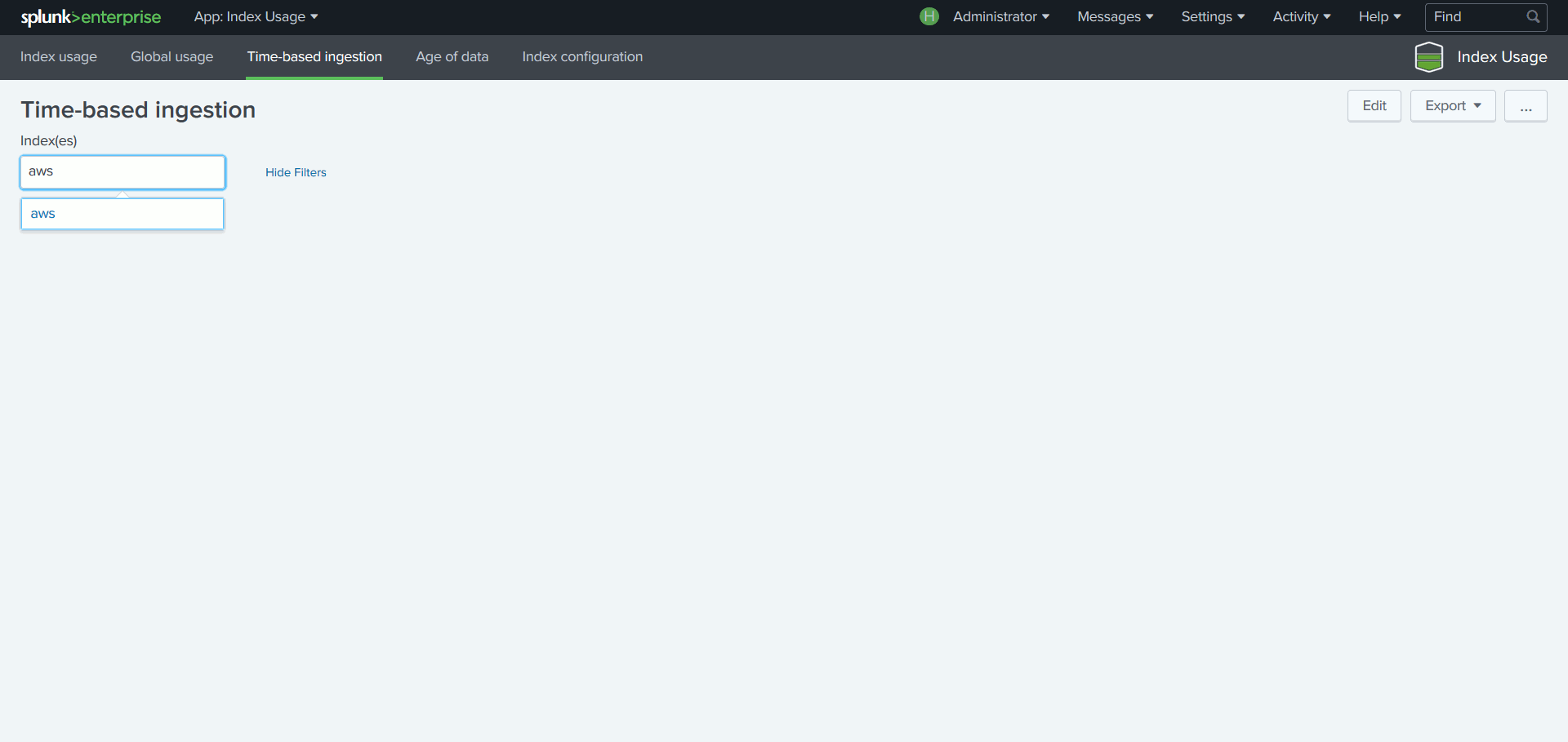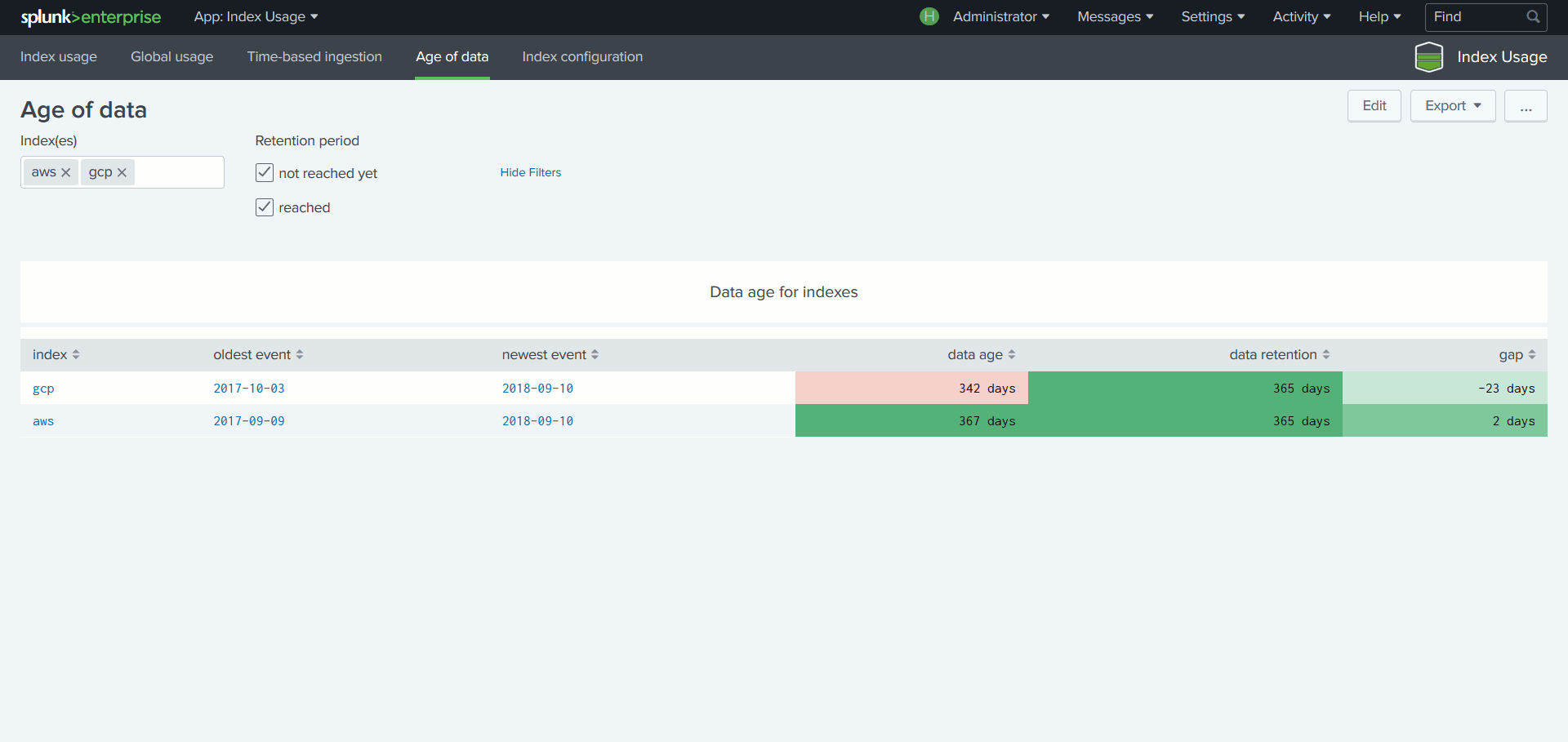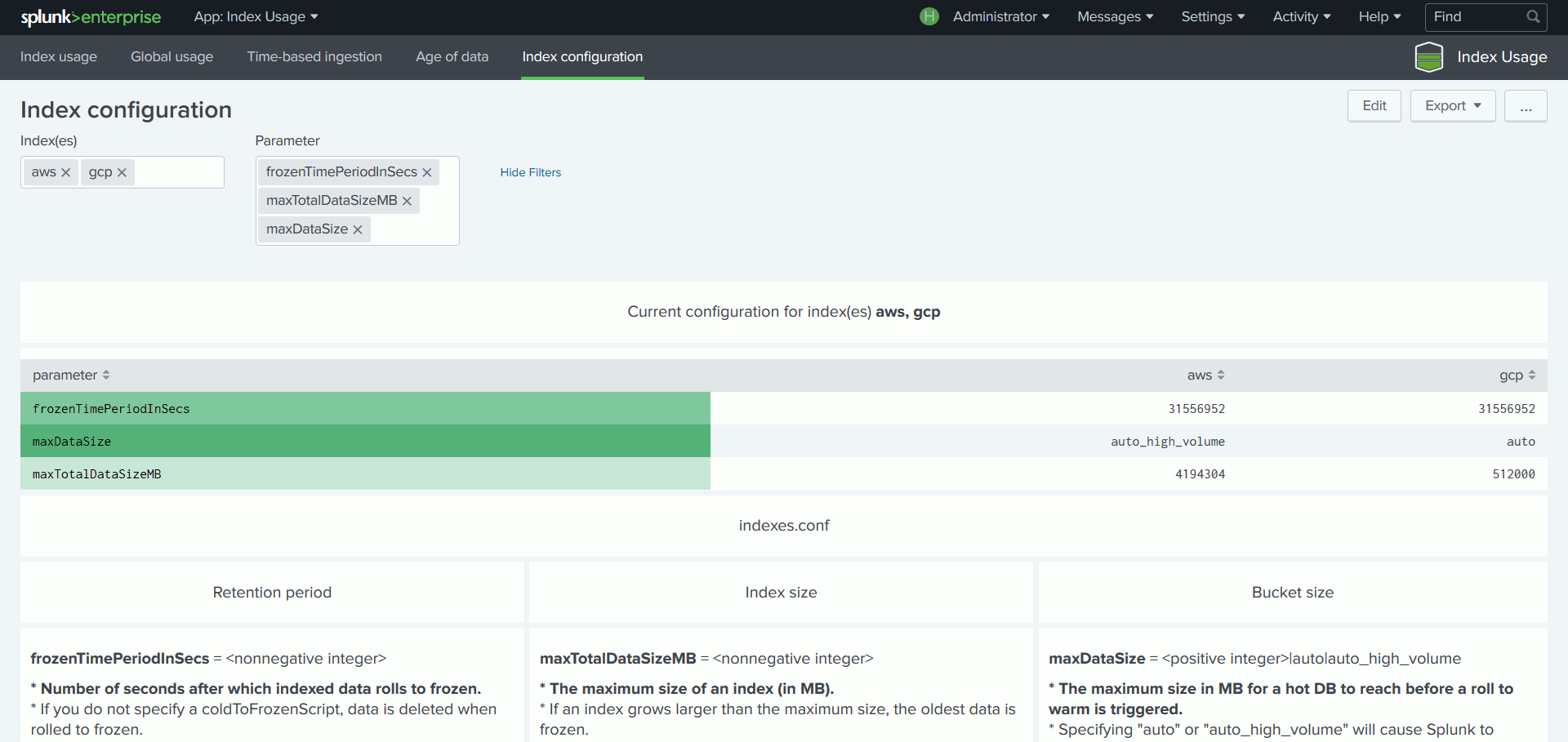
Lorsqu’un index atteint sa taille maximum, Splunk supprime les données les plus anciennes. Si elle n’a pas été souhaitée, cette suppression peut être la conséquence d’un sous-dimensionnement de l’index. Via la Console de Monitoring, il est déjà possible de surveiller le taux de remplissage de chaque index. Il suffit alors, pour éviter toute perte de données, d’augmenter la taille d’un index trop chargé. Cette opération reste toutefois manuelle et fastidieuse.
Pour en être épargné, il faut configurer correctement les index ce qui nécessite d’être en mesure de prédire leur taille finale. Cette dernière s’obtient en multipliant le volume journalier indexé par le nombre de jours de rétention, tout en prenant compte des paramètres s’appliquant à la plateforme considérée tels que la compression et la réplication. Mais il n’est pas facile, au moment de la configuration d’un index, de connaitre le volume de données qui sera ingéré, ni même d’en anticiper une éventuelle variation.
Pour pallier cette difficulté, l’App compare le volume moyen de données reçues par index – basé sur les 7 derniers jours –, à la configuration en place, ce qui permet, via différents tableaux de bords, de vérifier la conformité du paramétrage des index au regard des volumes réellement indexés ceci dans le but de minimiser les ajustements de configuration et d’éviter toute perte de données.
User Role Checker
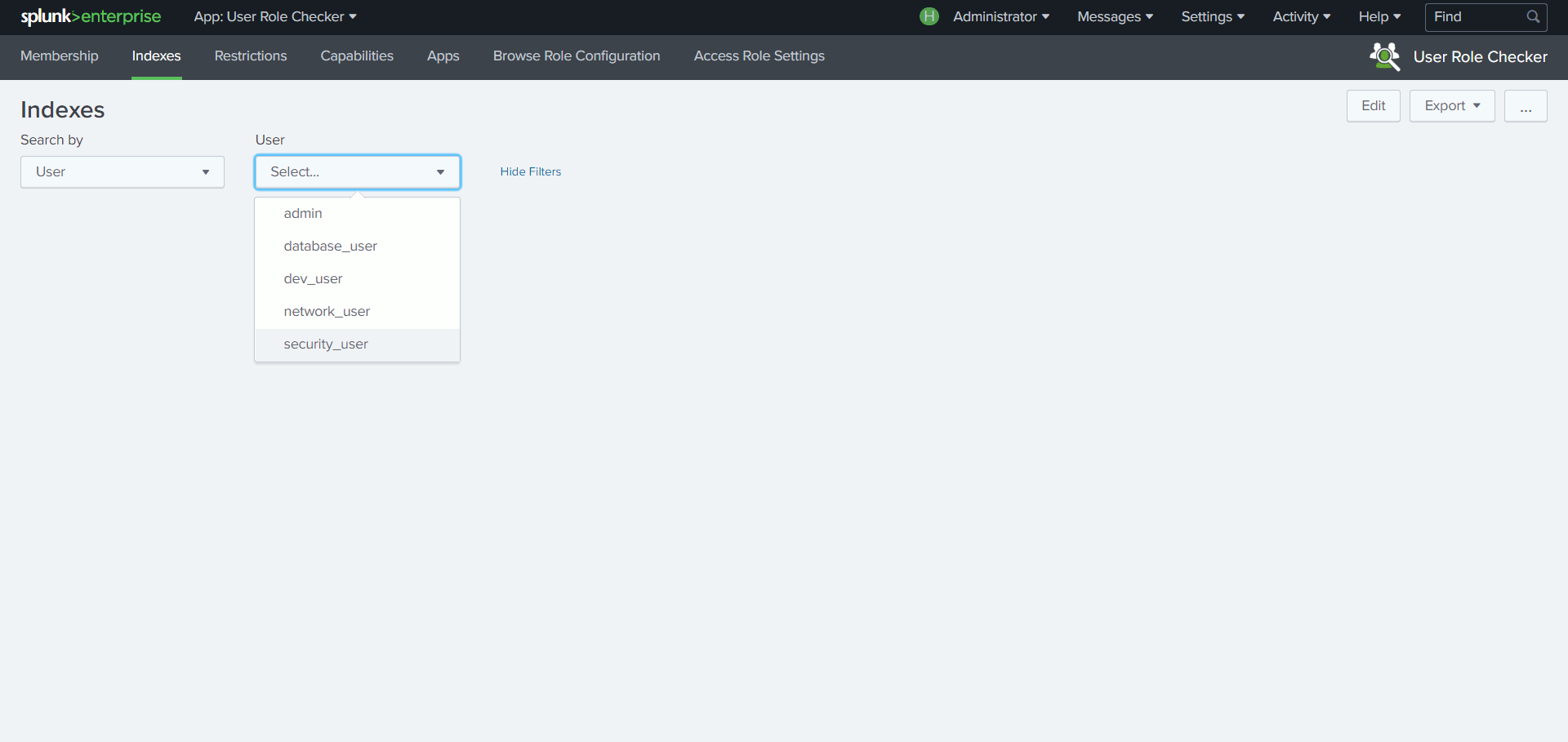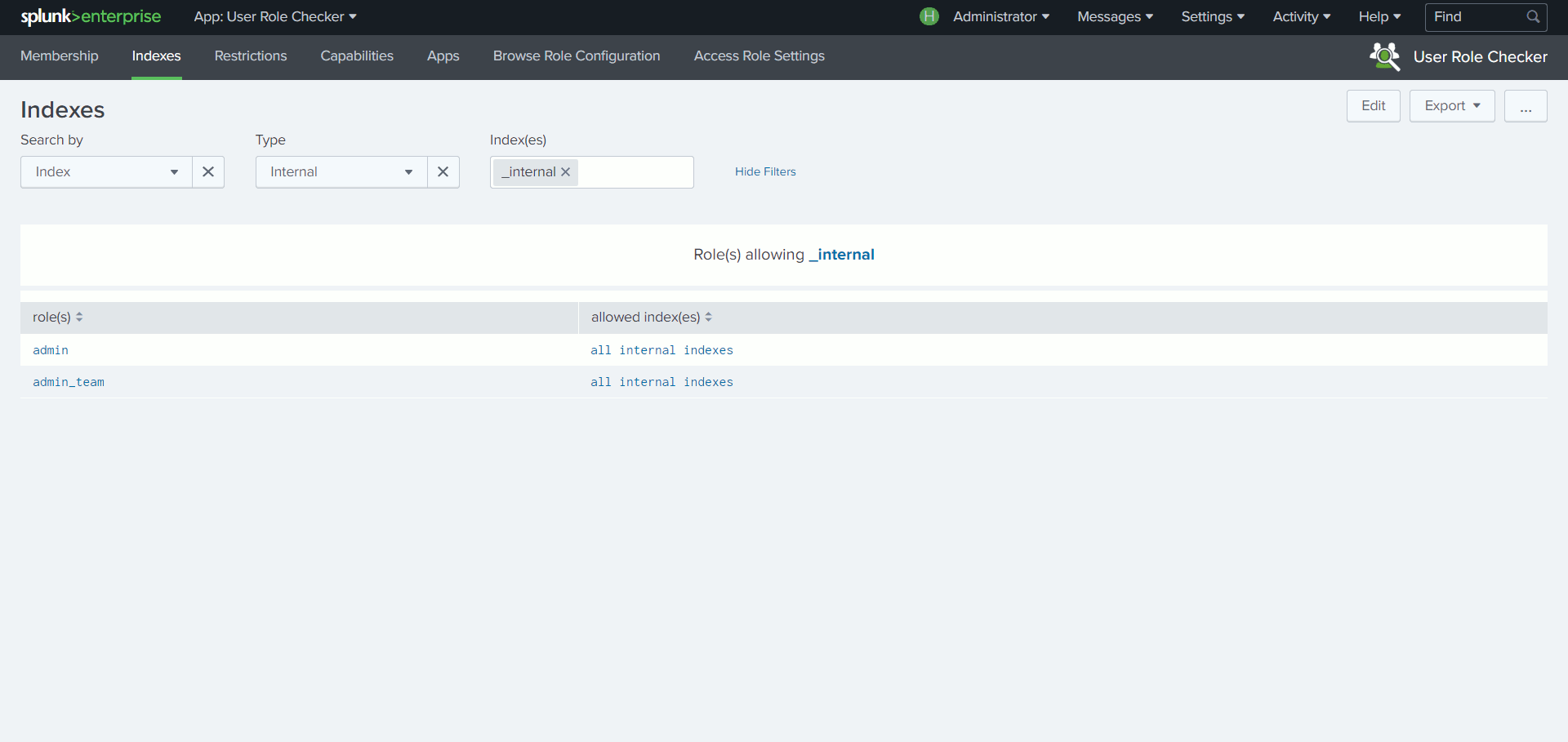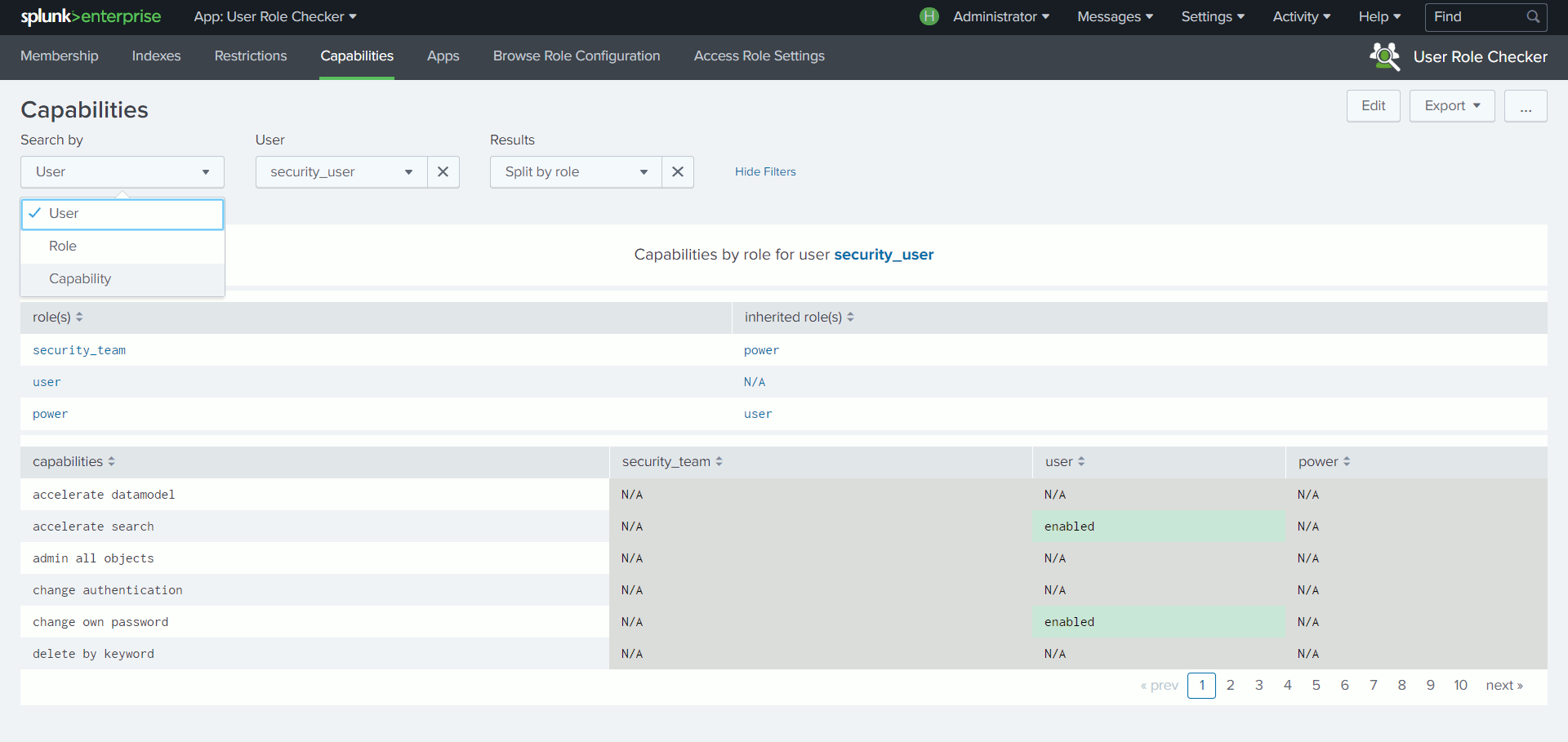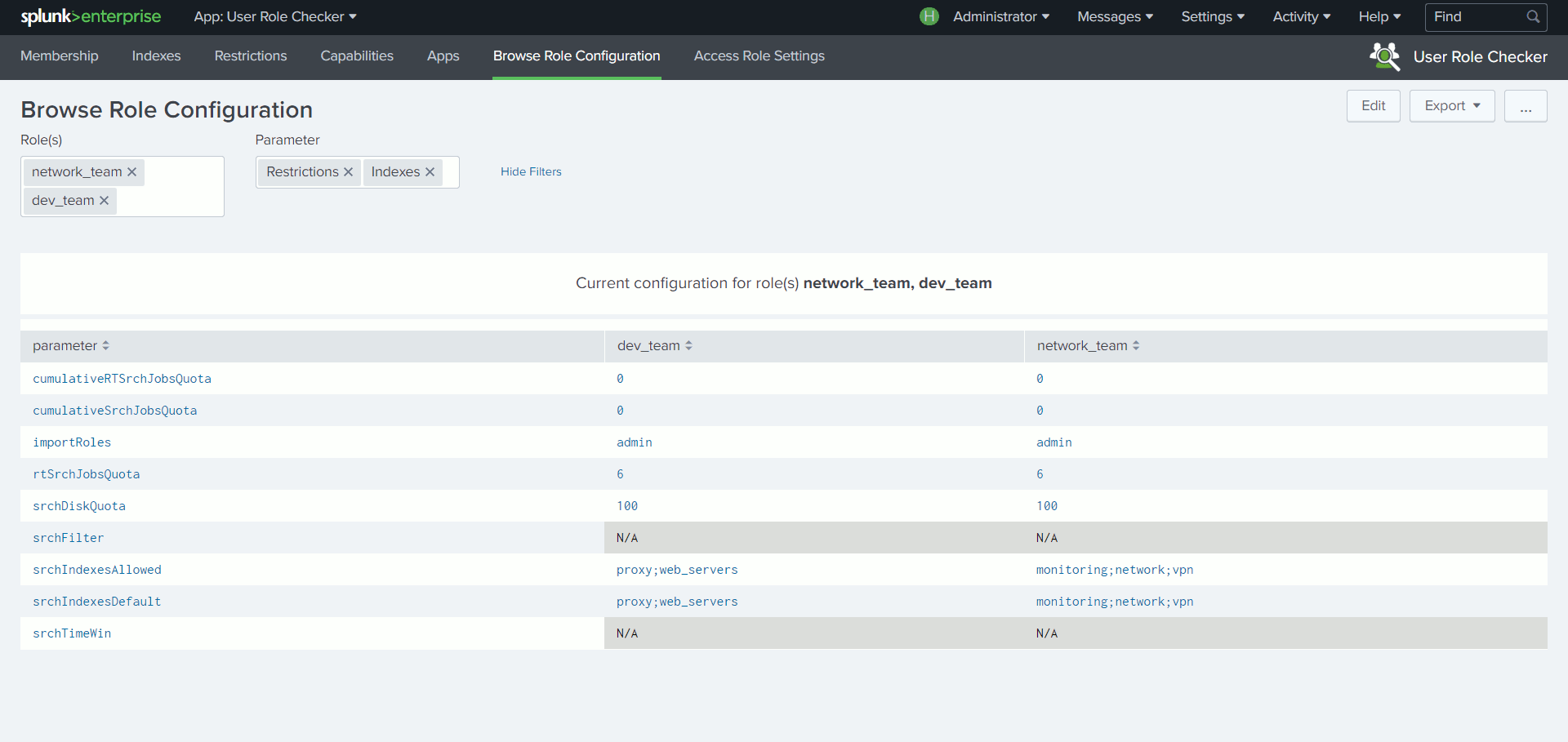
Du fait de l’héritage entre les rôles, il n’est pas toujours aisé de vérifier les droits ou les capacités attachés à un utilisateur ou à un rôle via l’interface Splunk.
Grâce à une structure de recherche basée sur des appels API prenant en compte cette notion d’héritage, cette App permet de découvrir en un coup d’œil, à partir d’un utilisateur ou d’un rôle, quels sont les index autorisés, les restrictions de recherche, les capacités ou encore les permissions sur les Apps.
Mad Props
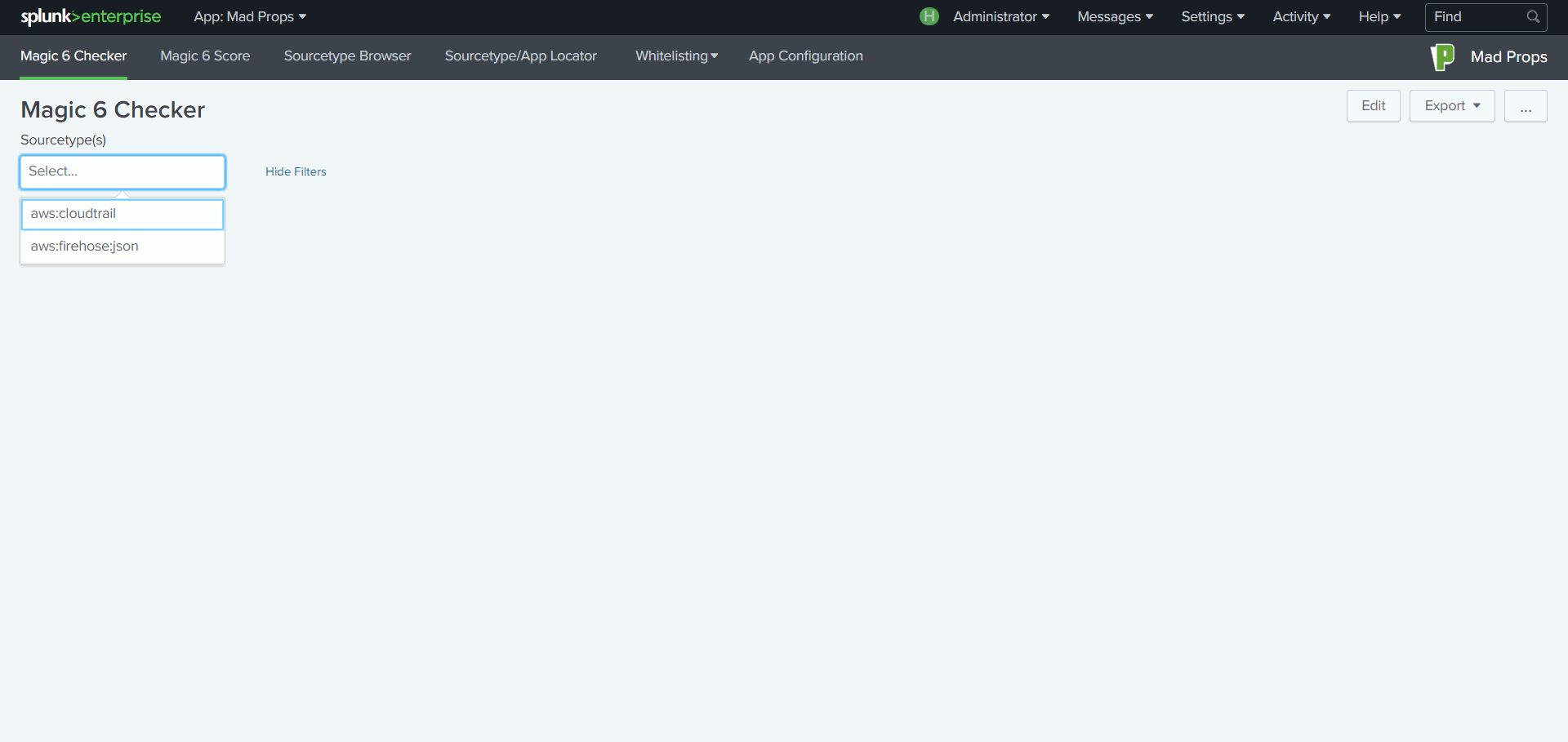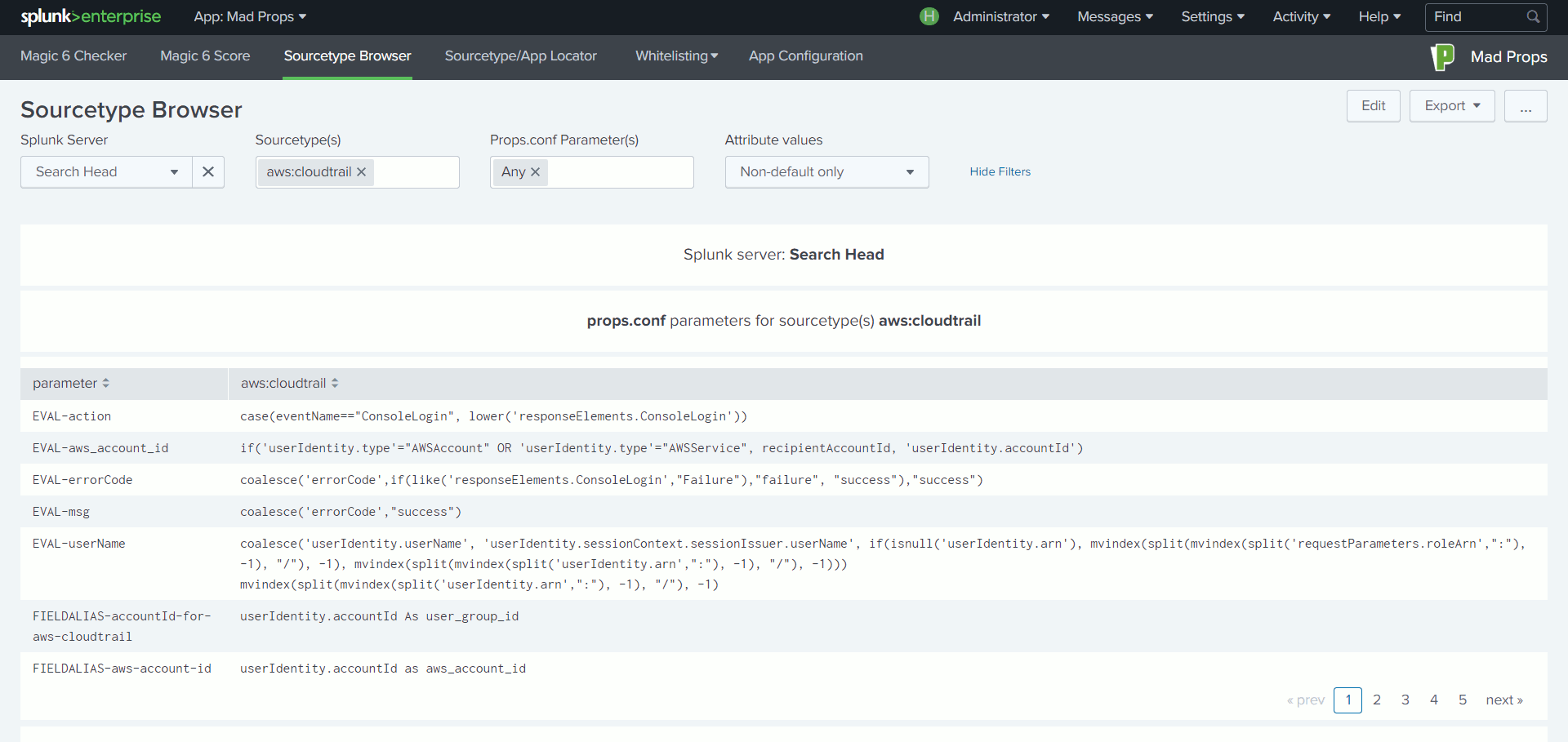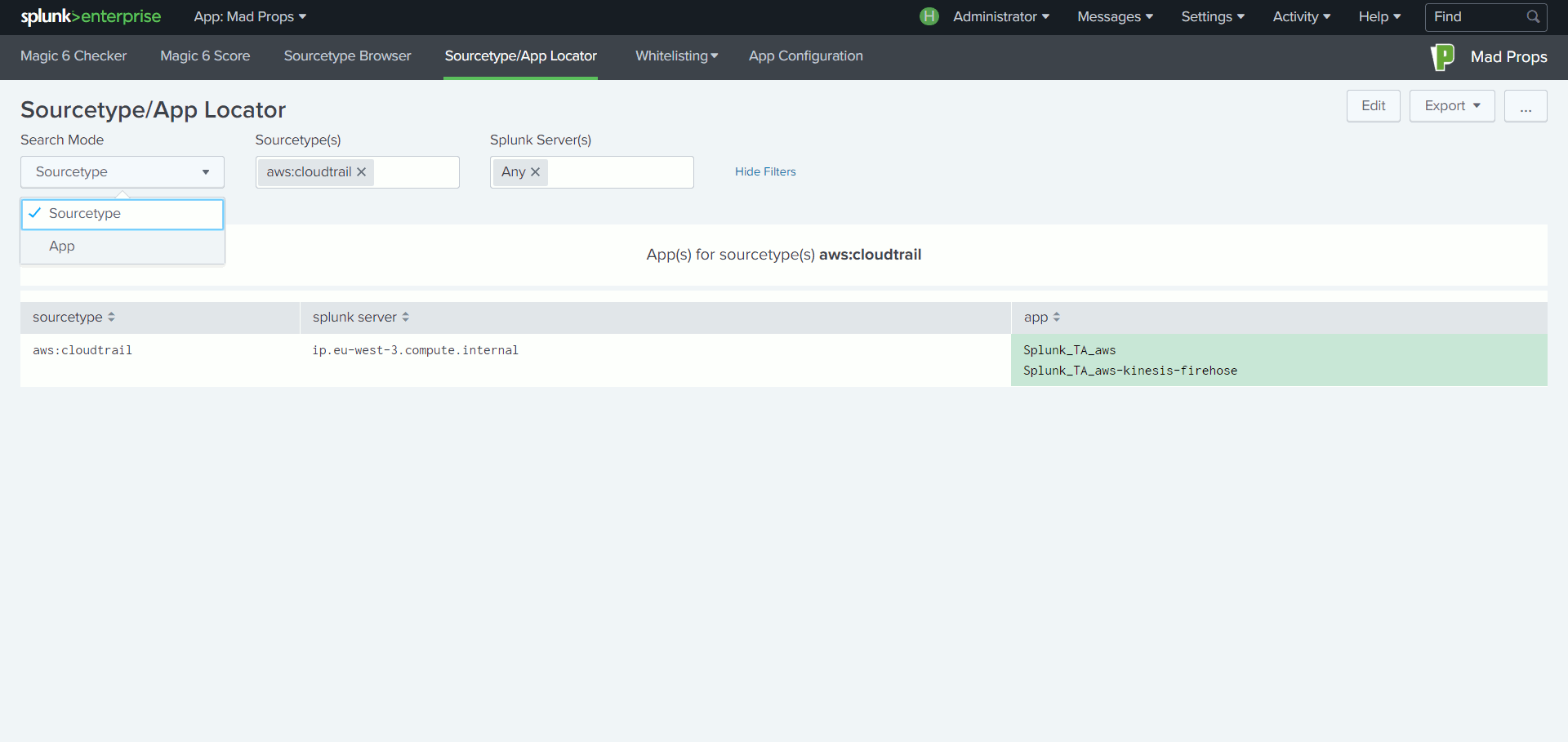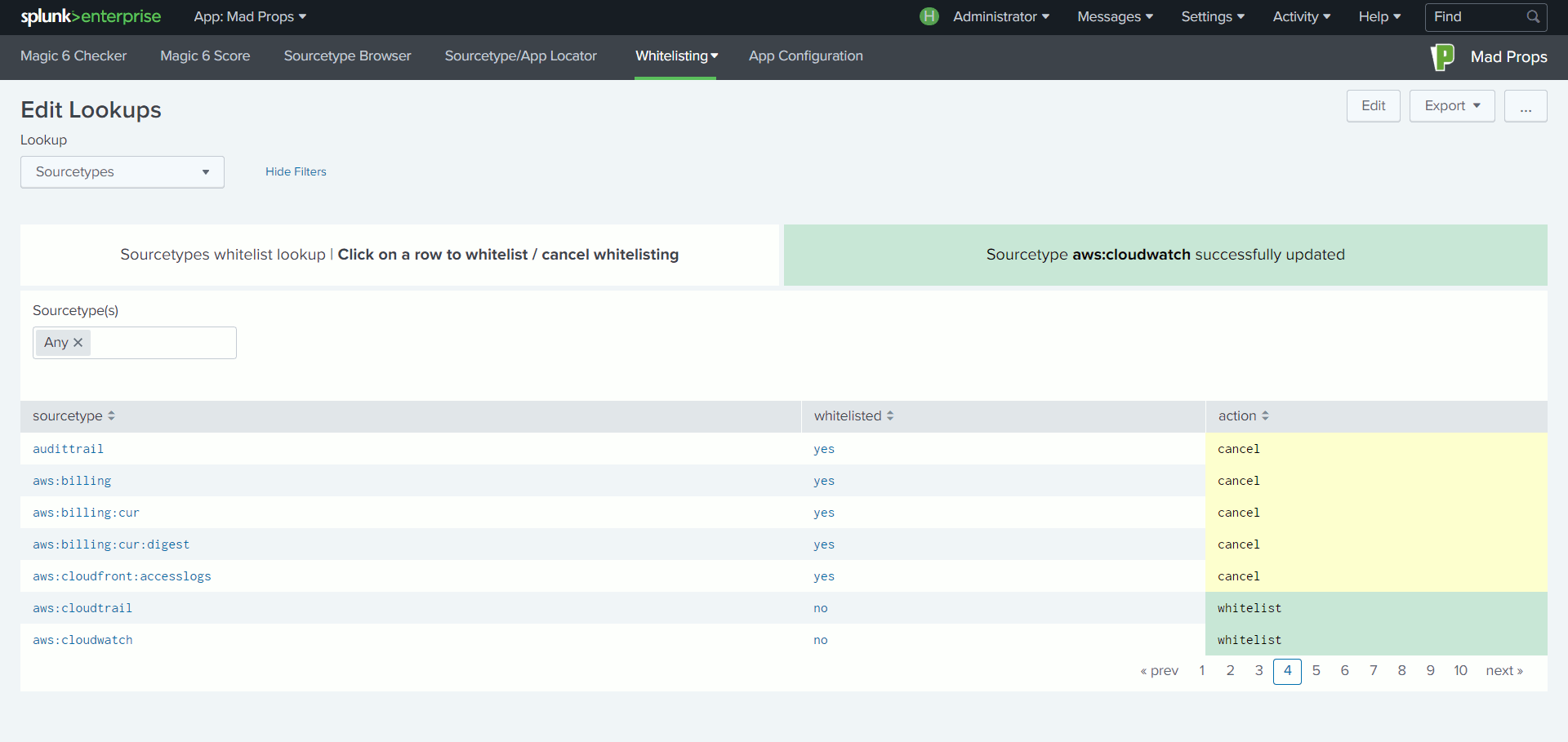
Lorsque l’on configure Splunk pour intégrer un nouveau type de données, il est recommandé de paramétrer six attributs du fichier props.conf : TIME_PREFIX, TIME_FORMAT, MAX_TIMESTAMP_LOOKAHEAD, SHOULD_LINEMERGE, LINE_BREAKER et TRUNCATE. En suivant cette bonne pratique, Splunk sait comment traiter les évènements et ne dépense pas des ressources précieuses en détection automatisée. L’indexation s’en trouve ainsi optimisée.
L’App propose donc, à travers plusieurs tableaux de bord, de suivre la configuration de ces 6 paramètres sur les différents types de données. Le but est de faire ressortir les types de données paramétrés de manière incomplète et de cibler ainsi les ajustements à effectuer.
Parallèlement, l’App propose un « navigateur » de type de données.
S’il est possible nativement de vérifier le paramétrage appliqué à un type de données, il faut parfois jongler entre plusieurs menus de l’interface avant de comprendre quels champs sont extraits pour un type de données, ou bien encore quelle table de correspondance s’applique.
Ce navigateur, permet, à partir d’un type de données sélectionné, d’afficher dans un même tableau de bord, l’ensemble des éléments de configuration appliqués.
Utilisation d’AWS User Data
Pour concevoir et tester ces Apps, nous nous sommes fortement appuyés sur AWS pour monter des instances Splunk de Lab jetables.
Il est en effet possible, lorsque l’on configure une instance EC2, de positionner un script shell qui est lancé après le démarrage initial. Nous avons donc écrit un script simple qui lance l’installation de Splunk et configure l’outil de manière à ce que le service soit accessible directement, en évitant les étapes associées à une nouvelle configuration. Le script permet aussi de récupérer le contenu d’un bucket S3 pourvu en Apps et Add-ons Splunk et d’installer ces composants.
Même si ce script reste très simple, il nous a été très utile et nous avons donc pris le soin de le publier.
Ces réalisations, disponibles via les liens proposés, ont été documentées de manière à faciliter leur prise en main. N’hésitez donc pas à les tester si leur but correspond à vos besoins.
Commentaires :
A lire également sur le sujet :






