
Machine Learning sur AWS : tour d’horizon des services et algorithmes Sagemaker

Tout le monde en parle, pourtant le Machine Learning reste un sujet très abstrait. Nous avons eu la chance d’assister au Meetup AI/ML, animé par Olivier Cruchant, Solutions Architect Specialist AWS, dans les locaux de D2SI Toulouse, nous vous proposons donc un aperçu sur l’écosytème du Machine Learning et les moyens de l’utiliser sur AWS.
Le machine learning, c’est quoi ?
Le machine learning consiste à prédire des événements à partir de jeux de données passées avec des algorithmes et des motifs d’apprentissage.
AWS souhaite fournir du machine learning à tous les développeurs et data scientists via un service à l’usage, plus accessible, plus sécurisé et plus performant qu’une solution développée en interne.
AWS compte déjà un nombre important de cas d’usages clients variés et étoffe régulièrement son offre en fonction de l’usage et de la demande de ses clients.
3 niveaux d’abstraction proposés
Les services AWS de Machine Learning se classent par familles, du moins complexe au plus complexe.
- Application services : à base d’API web, ils sont prêts à l’emploi, dans les domaines vision, langage & parole, chatbots, et autres.
- Platform services : Amazon Sagemaker, pour déployer des modèles d’apprentissage pré-établis, de l’entraînement, des réglages et de l’inférence (la déduction à partir des modèles et des nouvelles données). A noter également dans cette catégorie, AWS DeepLens, la caméra IoT connectée et embarquant de l’inférence @edge (un peu comme un device Greengrass de machine learning prêt à l’emploi sur les cas d’usage image et vidéo), et l’interfaçage avec Mechanical Turk, le service de tâches manuelles à la demande, pour de l’apprentissage supervisé par un humain (pensez classification des images hotdog / not hotdog mais en plus complexe).
- Frameworks & infrastructure : Développer et déployer ses propres modèles à partir de briques de base AWS, comme des AMI dédiées au Deep Learning, des types d’instance EC2 optimisées (P3 avec puces nvidia tesla v100 accélérant les produits matriciels), frameworks de développement tels que pytorch, TensorFlow, MXNet,…
Un rapide aperçu des Services
Ils sont découpés en grandes familles fonctionnelles :
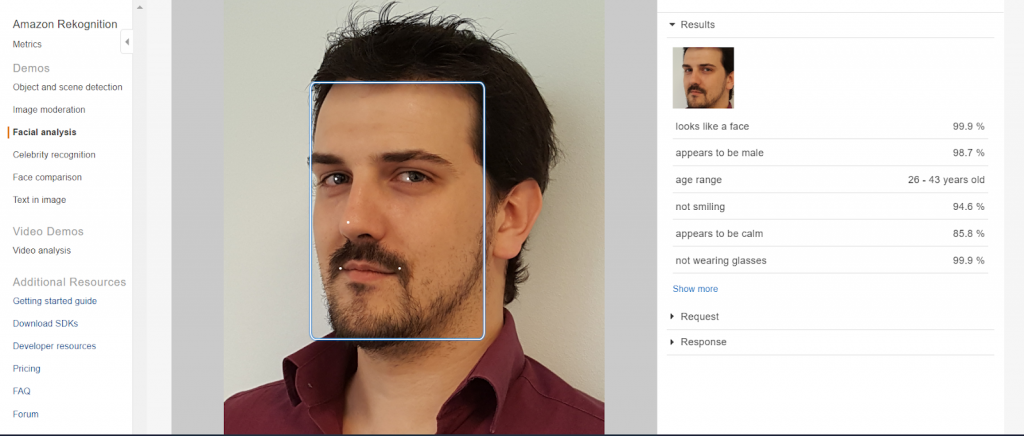
- Reconnaissance : Rekognition pour les images (étiquetage d’une scène, de visages, similarités), la video (idem image + tracking des objets, type d’activité), Textract (OCR avancée avec mise en forme automatique, en preview)
- Voix : Polly (text-to-speech avec choix de voix, réglages avancés sur la prosodie c’est à dire la vitesse, l’intonation, le rythme, les respirations), Transcribe (speech-to-text, formatage et ponctuation auto, multi-participants, pour sous-tirages automatiques)
- Langage : Lex (analyse et moteur de conversation, utilisé pour des chatbots, pour Alexa), translate (traduction audio temps réel ou en batch, détection de langue), Comprehend (analyse de conversation, détection de phrases clé, de sentiment, regrouper des articles par sujet principal, …)
- Prévisions : Forecast (prédiction à partir d’un historique de données dans le temps ou time series et de modèles d’extrapolation)
- Personnalisation : Personalize (recommandations personnalisées, toute la partie scientifique de calcul et de gestion de la matrice produits/users (on reviendra sur cette notion plus loin dans l’article) est déjà gérée donc plus facile d’accès)
Les 3 phases du Machine Learning
Un projet de Machine Learning comprend en général 3 grandes phases :
- Création de modèles / développement (build) dont
- la collecte et la préparation la donnée
- le choix et l’optimisation d’un algorithme
- Apprentissage via absorption de données (train) dont
- la configuration et gestion des environnements d’entrainement
- l’entrainement et réglage du modèle
- Utilisation (deploy) dont
- déploiement du modèle en production
- mise à l’échelle et gestion des environnements de production.
Selon le type de service utilisé, l’utilisateur devra plus ou moins s’investir dans chaque phase.
Nous avons vu que dans le cas des Application Services, seule l’utilisation de l’inférence était sous la responsabilité de l’utilisateur, tout le reste étant managé. Voyons comment cela se traduit pour les Platform Services.
Les services plateforme : SageMaker
Sagemaker se définit comme un orchestrateur de tâches de machine learning, très flexible.
Il s’utilise via :
- la console aws
- la CLI AWS : aws sagemaker action
- SageMaker python SDK
- Boto3 python SDK, moins spécialisé que le SDK SageMaker mais plus bas niveau.
Si on reprend les 3 phases dans un projet ML, comment s’appliquent-elles à SageMaker ?
En phase de build, Sagemaker propose du code pré-construit mais du code opensource est possible. Dans ce dernier cas, le choix du framework a de l’influence sur la scalabilité et l’utilisateur devra tester et choisir le plus adapté, Sagemaker fournit la plateforme.
En phase de training, SageMaker fournit un one-click training. On trouve 2 types de paramètres dans un modèle : les classiques, qui sont les entrées de configuration de smodèles, et les hyperparamètres qui dimensionnent les modèles.
SageMaker intègre un processus d’optimisation qui parcourt la zone d’hyperaramètres à la recherche du meilleur cas de performances.
En phase de déploiement, le modèle qui a été créé dans un bucket s3 peut être déployé où l’on veut. On peut générer un endpoint http pour utiliser le modèle à la demande et fournir de l’inférence en temps réel.
La mise à l’échelle est gérée par AWS, non pas en serverless, mais via des instances.
Les Frameworks et infrastructure
Ici, on travaille à plus bas niveau, ce qui rend très libre mais avec un travail de configuration plus important.
La phase exploratoire du build du modèle utilise fréquemment le framework Jupyter notebook (anciennement ipython) permettant de mélanger prise de notes, code interactif et graphes en ligne.
On peut y intégrer des éléments Tensorflow.
On lance ensuite de l’entrainement via des containers mêlant du code, des scripts et du sdk tensorflow par exemple.
A noter la sortie pour SageMaker de Tensor Flow Script Mode qui simplifie l’utilisation en se rapprochant des scripts tensorflow tels qu’utilisés dans d’autres écosystèmes.
Coder son modèle n’est pas indispensable, on peut entrainer et déployer un modèle builtin. Le code n’est pas publié par AWS, et il n’y a pas de benchmarks officiels, mais en général la performance constatée est dix fois meilleure que le même code en opensource.
Certains frameworks ont des images docker préconfigurées pour gagner du temps de mise en place et gestion.
On a alors le choix entre déployer :
- son propre code dans un framework container
- son propre code dans son propre container
- un code dans une ressource préfabriquée issue du Marketplace
L’optimisation des coûts est à prendre aussi en compte. On pensera à tagguer les ressources et exécuter des fonctions lambdas pour automatiser la gestion d’infrastructure (allumage / extinction).
Le développeur de Machine Learning dispose donc de beaucoup de liberté et de variété dans les méthodes. En suivant la documentation et les tutoriels, l’approche peut souvent varier, ce qui laisse la possiblité de choisir telle ou telle méthode selon ses préférences, que ce soit sur la partie code scientifique que sur la partie code de déploiement / maintenance.
Les types de modèle se prêtent mieux à certains optimisations et donc à certains matériels. On optimisera un modèle après entrainement selon le matériel choisi pour l’exécuter in fine.
AWS propose également le service Elastic Inference via du GPU à la demande. Vu que le calcul de la phase d’inférence est peu prédictible, on peut grandement optimiser ses coûts en utilisant des moyens de calcul élastiques lors de cette étape.
Dans les service AWS connexes, on peut aussi noter IoT Greengrass qui permet l’application de Machine Learning at edge sur des objets connectés.
Quelques algorithmes et cas d’usages
En date, 18 algorithmes sont disponibles déjà implémentés par AWS, pouvant se classer en 2 familles :
- les supervisés : on sait ce qu’on cherche et on récompense l’algorithme quand il trouve correctement parmi les données analysées.
- les non supervisés : on cherche une optimisation générale sur un ensemble d’objets pour lesquels on ne sait pas encore appliquer de tri. On va alors laisser la machine faire émerger des groupes d’objets selon des métriques autosélectionnées par elle.
Chaque algorithme est accompagné d’une documentation et d’au moins un tutoriel.
Il est souvent possible d’utiliser un algorithme dans un cas d’usage pour lequel il n’a pas été intuitivement prévu au départ, c’est là que le savoir-faire de conceptualisation et de modélisation mathématique apporte sa valeur ajoutée.
Prenons l’exemple d’algorithmes de travail sur une suite de mots vue comme une séquences de tokens, tels que les cas de traduction, où on traduit une séquence en une autre séquence. Ils sont aussi applicables à d’autres usages, tels que les gestions de produit.
En effet, si on considère qu’un token représente un produit de catalogue, on constate alors que la suite de consultation de produits (historique) est une phrase, qu’un panier de produits est aussi une phrase. Les modèles d’analyse de texte sont alors aussi applicables à ces cas d’usage.
Voici un rapide descriptif des principaux algorithmes, je vous renvoie à la documentation pour plus de détails.
Exemple : Object detection. Dessiner des boites (bounding box) autour d’objets reconnus
Ce type d’algos peut être pré-entrainé avec des catalogues d’images déjà existants (banque imagenet), on parle alors de transfer learning.
On a également la possibilité de faire de la détection à entrainement zéro (non supervisé donc), car certains clusters de données se détachent parfois tout seuls (exemple : visages sans et avec lunettes présentent des paramètres très divergents).
Exemple : DeepAR
Pour des prévisions sur des timeseries scalaires, afin d’extrapoler les données à venir. Permet de détecter notamment les tendances et les répétitions de motifs.
Exemple : Blazintext Word2vec
Permet la prédiction de mots manquants dans un texte basés sur la proximité de mots dans un corpus de texte.
Là aussi, c’est applicable à un panier de produits pour de la suggestion de produits similaires ou achetés par d’autres clients.
Exemple : blazingtext classification
Prédire un label d’intérêt sur une suite de mots tels que du sentiment, du code d’erreur, de l’importance.
L’ordre des mots n’a pas d’importance (bag of words), l’analyse peut intervenir sur les mots ainsi que les paires de mots.
L’algorithme équivalent en accélération GPU est fasttext.
Exemple : Object2Vec
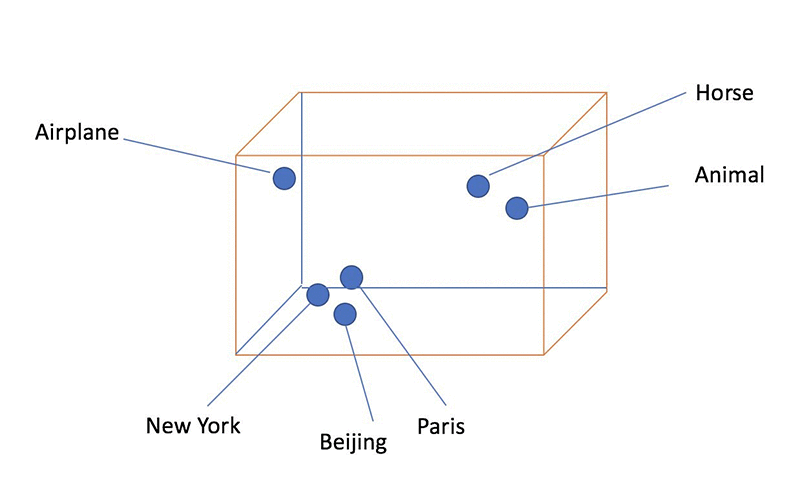
Générer des prédictions sur des objets variés. Créer un label soi-même.
Dans le cas de recommandation de produits, en substituant un userid par la séquence de produits vus, on anonymise un historique et on peut alors lier un nouveau produit suggéré à une séquence d’autres produits.
Exemple : Random cut forest
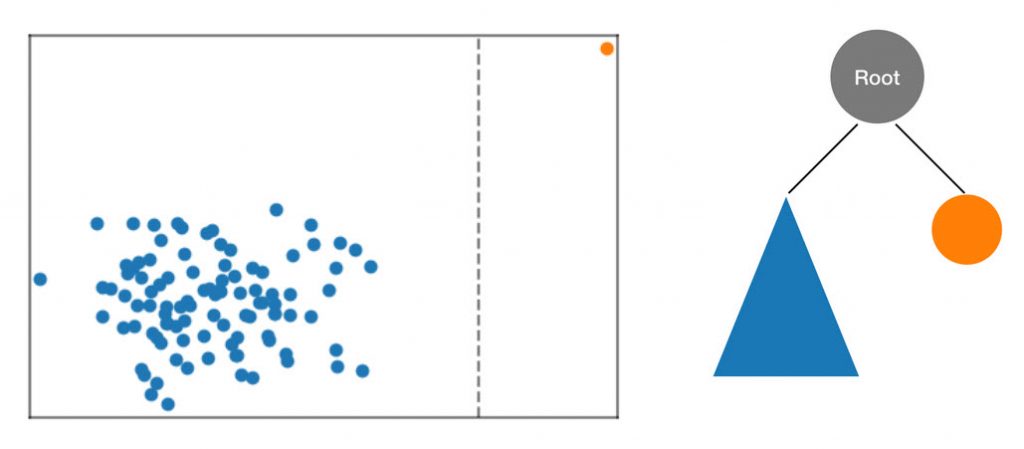
Détection d’anomalie, on va utiliser l’aléatoire pour détecter un problème. On partitionne un dataset par cuts aléatoires, les éléments seuls lors d’une coupe sont alors des feuilles, et on peut détecter l’éloignement de la feuille à la racine selon la durée qu’il aura fallu pour obtenir cette feuille. Plus la feuille est loin de la racine et plus l’objet est une anomalie par rapport au reste des objets.
On peut aussi souligner deux sous-services de Sagemaker :
- Sagemaker groundtruth
Il faut souvent partir d’un dataset de référence pré-étiqueté comme point de comparaison des objets à analyser. Ground Truth propose des moyens d’étiqueter ce jeu de données de référence de façon industrialisée.
- Sagemaker neo
Une fois un algorithme entrainé, et une cible d’exécution choisie, neo propose de compiler le code algorithmique de façon optimisée pour cette cible et ainsi gagner en temps d’exécution (jusqu’à 2x plus performant), ce qui peut permettre des applications embarquées de machine learning at edge.
Pour aller plus loin
On se rend vite compte que le sujet du Machine Learning est vaste et ses possibilités riches, mais qu’il n’est plus réservé aux seuls spécialistes et qu’on peut choisir le service à utiliser selon son niveau de connaissances et la complexité du sujet à traiter.
Quelques adresses sur le sujet :
- La chaine YouTube d’AWS, mots clés AI et/ou ML
- Le blog AWS dédié au Machine Learning
- Le site d’AWS SageMaker
- « An interactive deep learning book with code, math, and discussions«
Commentaires :
A lire également sur le sujet :






