Structurer son projet Terraform

Dans cet article, nous supposerons que vous avez déjà des connaissances sur Terraform, et que vous l’avez déjà utilisé, au moins de façon basique. Vous connaissez Plan et Apply, ainsi que les variables et les states par exemple.
Après avoir compris les principes de base de Terraform, je me suis posé la question suivante : comment organiser mon code proprement pour qu’il reste lisible et exploitable ? Cet article a pour objectif de répondre à cette question.
Cet article ne prétend pas amener La réponse, plusieurs approches peuvent répondre aux problématiques abordées. Je présente ici l’état, à ce jour, de ma réflexion sur ce sujet. Libre à vous de vous en inspirer ou de partager vous retours d’expériences et conseils en commentaires.
Rationalisez vos fichiers
On commencera donc par la « rationalisation » des fichiers. L’idée ici est d’avoir des fichiers distincts pour chaque fonction, avec un nommage spécifique permettant de garder un ordre de présentation communs aux différents projets.
Un exemple étant souvent plus parlant :
├── 00_variables.tf
├── 01_providers.tf
├── 02_remote_states.tf
├── 10_main.tf
├── 11_s3.tf
├── 12_rds.tf
├── 88_tfstates.tf
├── 89_outputs.tf
├── README.md
├── secrets.tfvars
├── terraform.common.auto.tfvars
├── terraform.production.tfvars
└── terraform.staging.tfvars
J’utilise un découpage par type de ressources et des prefix xx_ pour que s’affichent en premier les fichiers relatifs aux inputs (variables, remotes states) puis les définitions concrètes de mes ressources (main, s3, rds) et finalement les states et outputs.
Ensuite un Readme et des fichiers .tfvars permettent d’organiser les variables du projet (on y arrive juste après).
Cette structure permet de gagner en lisibilité. Dussé-je (#imparfaitdusubjonctif) intervenir sur ma base RDS ou sur mes outputs, je sais directement quel fichier ouvrir.
Organisez vos variables
En l’état je considère trois catégories de variables. Celles qui sont pré-déterminées, celles qui varient en fonction de l’environnement et les secrets. J’aurais donc trois types de fichiers de variables en plus du fichier permettant l’instanciation de ces dernières.
Le fichier 00_variables.tf assume ce rôle. Il sert à instancier les variables, à définir leur type et à en donner une description. L’idée est d’avoir une liste exhaustive des variables et de leur fonction sans gérer leur valeurs. On lit ce fichier pour savoir si une variable existe et a quoi elle sert, pas pour savoir quelle valeur elle a.
Les variables « pré-déterminées » ne sont a priori pas amenées à changer mais sont utilisées pour ne pas ré-écrire une valeur en dur à plusieurs endroits du code. Par exemple la région AWS apparaît régulièrement dans les ressources mais reste souvent la même. J’utilise dans ce cas le fichier terraform.common.auto.tfvars pour définir ces variables communes. Ce type de fichier correspond à des valeur « par défaut » pour tous les environnements.
Les fichiers dont l’extension est .auto.tfvars sont automatiquement chargés comme fichiers de variables par Terraform et évitent donc de spécifier la prise en compte de ces derniers via CLI lors du déploiement.
Pour les variables dont les valeurs varient en fonction de l’environnement j’utilise des fichiers terraform.<ENV>.tfvars. Chaque fichier contient les valeurs à utiliser pour l’environnement concerné et doit être explicitement passé en paramètre via l’option –var-file : terraform plan --var-file terraform.staging.tf.
J’utilise finalement un fichier secrets.tfvars pour gérer les valeurs des variables sensibles. Généralement ce fichier n’est pas inclus dans le versionning du code. Il est géré par un autre biais, par exemple généré à la volée lors du déploiement.
Pour résumer :
- 00_variables.tf : pour lister et expliciter les variables
- terraform.common.auto.tfvars : pour définir les valeurs communes
- terraform.<ENV>.tfvars : pour gérer les différences entre les environements
- secrets.tfvars : pour décorréler les variables sensibles
Utilisez des modules
Les modules peuvent être externes (tirés depuis une url) ou locaux (définis par un chemin sur le disque).
Ils permettent de grouper des définitions de ressources afin d’éviter la duplication de code ou pour tirer parti d’un travail déjà réalisé par une autre équipe, tout en imposant un certain standard.
Prenons un exemple pour illustrer rapidement le fonctionnement des modules et comment les intégrer dans notre arborescence.
Supposons un module nommé labels qui prend deux variables en entrée, les noms de tags projet et environment, et qui renvoie en output une map, nommée tags, de l’ensemble des nom:valeur pour chaque tag.
Pour les modules locaux je crée un répertoire modules à la racine de mon projet puis un sous dossier pour chaque module. Dans mon exemple j’ai donc :
racine
├── modules
│ └── labels
│ ├── 00_variables.tf
│ ├── 10_main.tf
│ ├── 89_outputs.tf
│ └── README.md
Je peux ensuite appeler ce module comme suit dans mes manifestes (souvent dans le main.tf) :
module "labels" {
source = "../chemin_relatif/modules/labels"
project = "terraform-skeleton"
environment = "${var.environment}"
}
Le paramètre source permet de spécifier où trouver le module, ici un chemin relatif sur le disque par rapport au fichier où l’appel du module se fait.
Les autres paramètres correspondent aux variables définies dans le module, ici projet et environment.
Je peux ensuite appeler directement l’output du module dans mes définitions avec une syntaxe du type : module.<NOM_DU_MODULE>.<NOM_DE_L'OUTPUT>, dans notre exemple l’output se nomme tags et on peut donc y accéder de la manière suivante :
resource "aws_instance" "test" {
[...]
tags = module.labels.tags
}
Dans ce cas précis l’utilisation d’un module pour gérer les tags permet de garder une consistance de nommage entre les différents projet et les différentes stacks.
Découpez en Stacks
L’idée des stacks est de pouvoir découper la gestion des ressources en fonction de leur cycle de vie ou des équipes qui en sont responsables. Les ressources réseaux et les ressources serveurs ne seront pas toujours gérées par les mêmes personnes, et il n’est pas nécessaire de redéployer tous les subnets pour modifier le nombre de serveur web par exemple.
Il est possible de grouper ces ressources en « sous projet » qui auront chacun leur cycle de vie (plan, apply, …) et des faire transiter des informations entre chaque stack via les states, chaque stack venant lire les outputs référencés dans le state de la stack précédente :
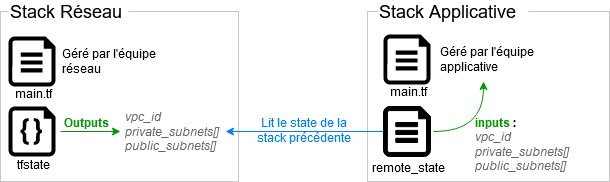
La mise en place de stacks passe, par exemple, par la définition d’une ressource terraform_remote_state :
data "terraform_remote_state" "stack_network" {
backend = "local"
config = {
path = "../000-network/terraform.tfstate"
}
}
Dans cet exemple le state de la stack précédente (000-network) est local, on configure donc la ressource en spécifiant le type de backend et le chemin vers le fichier concerné. Plusieurs types de backend peuvent cependant être utilisés de la même manière.
La récupération des outputs se fait en utilisant la syntaxe data.terraform_remote_state.<NOM_DU_REMOTE_STATE>.<NOM_DE_L'OUTPUT>, par exemple pour récupérer l’id d’un vpc :
module "terraform_enterprise" {
source = "hashicorp/terraform-enterprise/aws"
vpc_id = data.terraform_remote_state.stack_network.vpc_id
}
Un autre moyen d’utiliser les stacks est de taguer les ressources de manière précise et d’utiliser des datasource pour récupérer dans la stack courante des ressources créées dans une stack précédente. Au lieu de lire les outputs, on requête directement le provider en pré-supposant la création de ressources clairement identifiables.
Attention cependant lors de l’utilisation des Stack qui rajoutent des dépendances et une complexité accrue. On évite généralement de créer des liens « horizontaux », les structures en couche où chaque stack s’appuient sur une précédente plus générique posant des bases communes sont à préférer. On créé par exemple plusieurs stacks applicatives qui s’appuient sur une stack réseau commune mais on évite de créer des dépendances entre les stacks applicatives.
Créez des environnements
Dans la mesure du possible j’essaie de garder les environnements le plus ISO possible. Et donc d’utiliser le même manifeste par exemple pour le dev et la prod en conditionnant seulement certaines valeurs (nombre de serveurs, RDS multi-AZ, …).
C’est dans cette optique que sont utilisés les fichiers de variables terraform.<ENV>.tfvars. Ils contiennent la configuration spécifique à chaque environnement et sont donc appelés lors du déploiement en fonction du contexte : terraform plan --var-file terraform.\<ENV>.tfvars.
Le problème qui se pose rapidement est la gestion des states. Pour un fichier state local, si un environnement de dev a été déployé, et qu’un apply est lancé pour un environnement de prod, il y a conflit : le même fichier étant utilisé pour gérer l’état des deux environnements.
Ce point peut être adressé de deux façons :
-
En utilisant l’option backend-config lors du terraform init qui permet de définir une configuration spéficique pour le backend gérant les states. On crée alors plusieurs fichiers backend-<ENV>.tf pour chaque environnement et on en sélectionne un à l’initialisation du projet.
-
En créant des workspace Terraform, déléguant la gestion des states des différents environnement à Terraform lui-même. En l’occurrence un seul backend permet de stocker plusieurs states, Terraform créant un « sous répertoire » dédié à chaque.
La solution des workspaces me semble plus flexible pour gérer plusieurs environnements en local, mais l’option backend-config permet notamment une réelle séparation des states et me paraît plus fiable pour de la production, avec des déploiements via CI/CD.
En résumé :
- Gardez un unique manifeste pour tous les environnements
- Gérez les différences via des fichiers de variables nommés
- Séparez les states :
- via les workspaces :
terraform workspace [ new | select | show | delete ] - via plusieurs configurations de backend :
terraform init -backend-config "backend-<ENV>.tf"
- via les workspaces :
J’espère que cet article a pu vous donner quelques pistes de réflexions. N’hésitez pas à me faire vos retours.
A lire également sur le blog de Pierre si vous voulez automatiser le déploiement de votre code Terraform :
Déployer simplement son code Terraform avec Gitlab CI/CD
Commentaires :
A lire également sur le sujet :